Operační diagnostika
Co je myšleno pod pojmem operační diagnostika. Je o monitoring komunikační sítě včetně koncových zařízení a to za plného provozu.
Monitoring kritické komunikační infrastruktury a aplikací
Pokud máme řídit procesy kritických aplikací, musíme být schopni nejen monitorovat, ale řídit i komunikační infrastrukturu. Potřebujeme tedy nástroje, které nám požadované činnosti umožní. Je potřebné si uvědomit, že monitorovací nástroj (většinou programové vybavení) musí umět monitorovat nejen prvky sítě, ale i jednotlivá koncová zařízení, která řídí vlastní procesy. Je tedy nezbytné, aby monitoring byl schopen tato zařízení integrovat do sledovaného celku. Ne všechny monitorovací programy jsou toho schopny.
Navíc v mnoha případech je potřebné tento monitoring následně integrovat do celkového řídicího systému obvykle nazývaného SCADA -Supervisity Control and Data Acquisition. To je další požadavek, který mnoho monitorovacích systémů nesplňuje.
Nutnou a nezbytnou základní podmínkou realizace takového záměru je management všech prvků sítě i připojených řízených systémů. Představa některých uživatelů, že takovou síť lze postavit na unmanaged prvcích, je hodně mylná. Můžeme to nazvat přímo cestou do pekla. V reálném životě takové situace bohužel nastávají. Znám případ, kdy síť (naštěstí pouze administrativní) obsahující přes 350 živých IP adres je postavena ze Switchů bez managementu a ještě typu „každý pes jiná ves“. Síť tedy nelze rozdělit na VLAN, nelze monitorovat ani řídit, nelze prakticky vůbec nic. Řešení má pouze dva stavy. Buď síť funguje, nebo nefunguje. Pokud nefunguje, je velmi obtížné zjistit proč. Správců této sítě je mi opravdu upřímně líto. Každá drobná kolize znamená, že vyrazí po areálu firmy a hledají příčinu (většinou dlouho). Jediný pozitivní dopad je na jejich fyzickou kondici.
Pokusme si nyní říci, co by takový smysluplný systém operační diagnostiky v prostředí KKI měl umět a jaké by měly být jeho funkce a vlastnosti.
Mnoho takových systémů je schopno pracovat pouze v lokálním režimu, kdy je programové vybavení instalováno pouze na jednu řídící a monitorovací pracovní stanici. Tato varianta je pro systémy KKI naprosto nevhodná a má smysl pouze na notebooku servisního technika.
U rozsáhlých systémů je potřebné používat distribuované řešení. Pro distribuovaný dohled slouží architektura klient/server. To znamená, že na dohledu se může současně podílet větší množství operátorů, kteří sdílejí současně informace o stavu procesů. Větší množství operátorů zvyšuje předpoklad včasné registrace nově vzniklého problému v procesu. Informace týkající se správy sítě i řídících zařízení mohou být k dispozici v celé síti, nebo pouze ve vybraných segmentech sítě. Rovněž operátoři mohou mít přiřazenu odpovědnost pouze za určité specifické oblasti sítě i procesů. Uvedené řešení nabízí maximální flexibilitu.
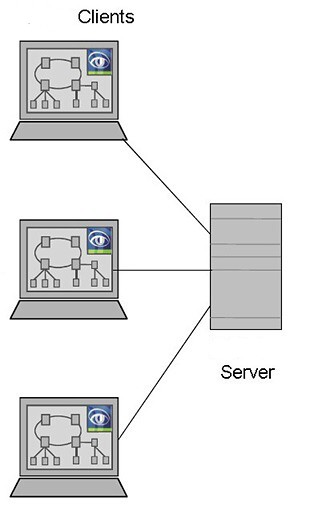
Pro KKI ovšem toto řešení nedostačuje. Server představuje kritické místo a při jeho selhání celý monitoring končí. V systémech kritických infrastruktur je nutné použít řešení s redundancí serverů. Podle míry rizika může být redundance až několika násobná.
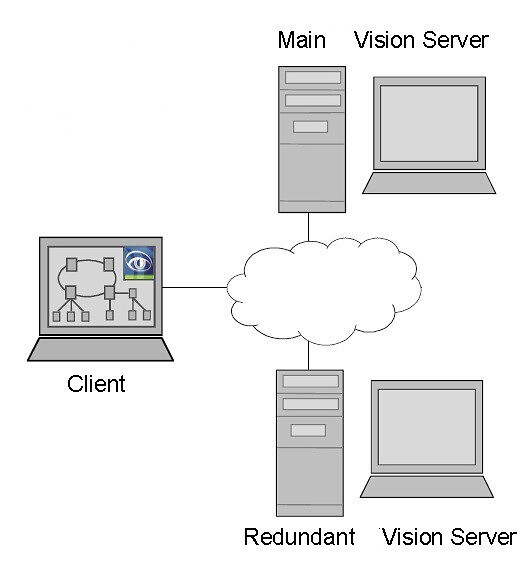
Další výhodou takového řešení je to, že klient obvykle nepotřebuje další žádnou licenci ani žádný speciální prohlížeč. Pro zobrazení mu dostačují grafická rozhraní běžných prohlížečů a přístup je možný i z mobilních zařízení.
Základním požadavkem je automatizované vytvoření mapy existující sítě. To představuje automatickou detekci všech zařízení v síti (zařízení mít alespoň MAC adresu), detekci komunikačních linek, jejich typu (TP, FO, WiFi) i jejich rychlostí, režimů (duplex) a stavů. Po detekci všech zařízení v síti musí automaticky vytvořit mapu topologie sítě, kterou již zobrazí v grafickém rozhraní.
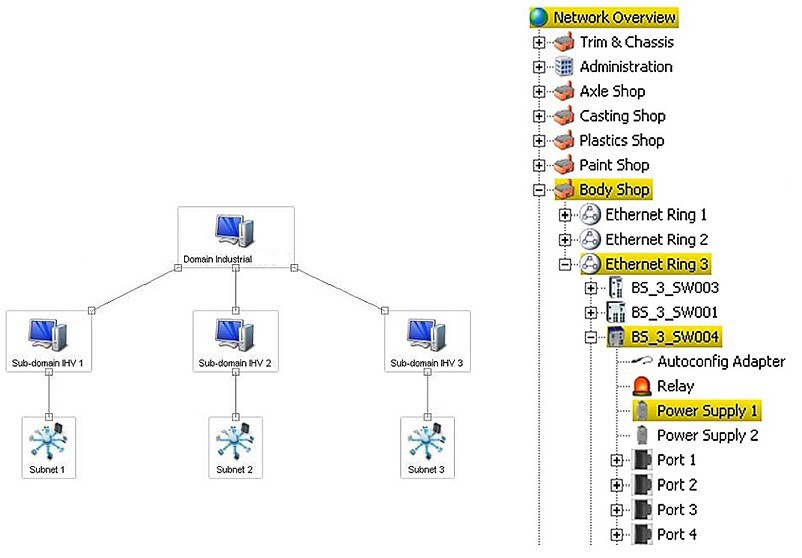
U rozsáhlých sítí je žádoucí i možnost hierarchického uspořádání sítě. Zobrazení rozsáhlé sítě na jedné obrazovce je z praktického hlediska nešikovné a hlavně nepřehledné. Většinou i v reálném prostředí není síť stavěna plošně, ale je složena z hierarchicky uspořádaných sub-sítí. Stejný způsob zobrazení je možný následně zvolit i pro monitoring.
Neméně důležité pro přehlednosti a čitelnosti mapy sítě je i zvýraznění zvolené VLAN a potlačení ostatních do pozadí.
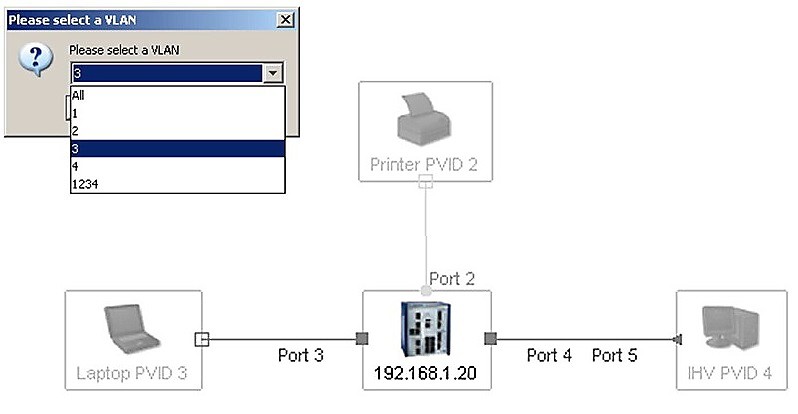
Od okamžiku prvního zjištění topologii sítě musí systém detailně dokumentovat všechny události, stavy jednotlivých zařízení a linek i všechny změny. Rozmístění prvků v grafickém zobrazení musí jít tahem kurzoru upravit tak, aby odpovídalo fyzickému rozmístění prvků. Takto upravené zobrazení reálné topologie sítě můžeme následně vytisknout a uložit do dokumentace sítě. V tomto kroku je velmi důležité, že topologie byla mapována automaticky. Nemohou v ní být tedy chyby, které mohou vzniknout při zpracování člověkem. Od spuštění program musí být automaticky detekována i nově připojená zařízení. Topologie je tedy neustále aktualizována a zobrazován je vždy reálný stav. Hovoříme o reálné mapě sítě. V rámci monitoringu sítě je potřebná i detekce typů portů, jejich připojení, detekce jednotlivých linek i WiFi spojů. Systém musí umožnit i správu bezdrátové sítě bez nutnosti dokupování dalšího speciálního software.
Detekce typů spojení
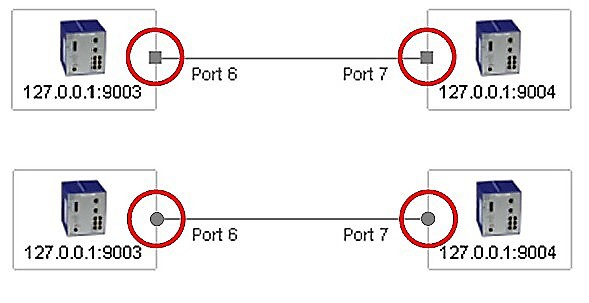
Detekce typů portu a linek, např. zakončení čtverečkem představuje metalický port, kroužek je pro optický port. Tloušťka čáry udává přenosovou rychlost.
Dobrý systém monitoringu dokáže odhalit i unmanaged Switche a jiná zařízení. U nich nelze automaticky rozeznat jednotlivé porty. Pokud takový prvek nějakým omylem (nebo hloupostí vlastní či cizí) použijeme v síti, budeme muset jeho porty definovat manuálně. To není až takový problém. Horší je to, že přijdeme o všechny monitorovací služby na všech linkách připojených do tohoto Switche. Pokud nemá Switch management, není schopen odpovídat na žádné dotazy monitorovacího programu.
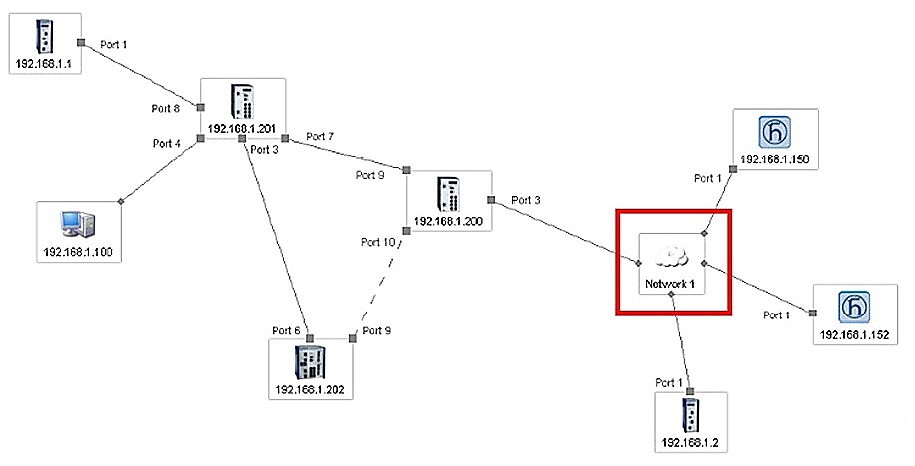
Nejvyspělejší systémy umožňují i naplánování sítě před její realizací a monitoringem.
Konfigurace prvků
Jednotlivé prvky KKI můžeme konfigurovat zařízení třemi způsoby. Pomocí webového rozhraní (SNMP) nebo CLI lze provádět individuální konfigurace jednotlivých zařízení. Tato metoda je při větším počtu zařízení pracná a zdlouhavá. Třetí možností je provedení konfigurací právě pomocí funkce MultiConfig systému operační diagnostiky. Tato alternativa přináší možnost konfigurace více zařízení (až všech) současně. Zařízení nemusí být stejného typu. Typická instalace s MultiConfig konfigurací zahrnuje teplotní limity, zákaz/povolení WEB interface, Multicast control, redundance, Device status, Trap destinace, Save configuration, nastavení VLAN a konfigurace portů atd.
MultiConfig portů
MultiConfig VLAN
MultiConfig hesla
MultiConfig protokolu redundance
Ukládání konfigurací pomocí MultiConfig (lze i obnovení tovární konfigurace)
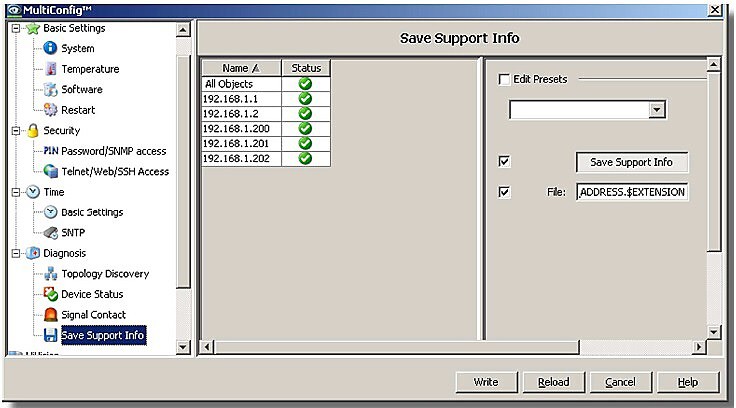
Důležitou a potřebnou funkcí MultiConfig je i správa a hromadné ukládání/nahrávání konfigurací jednotlivých prvků a zařízení sítě na úložiště. Lze tedy ukládat i pro rozdílné konfigurace k jednomu prvku, správu a členění podle adresáře, data/času, IP adresy, přípony konfiguračního souboru atd.
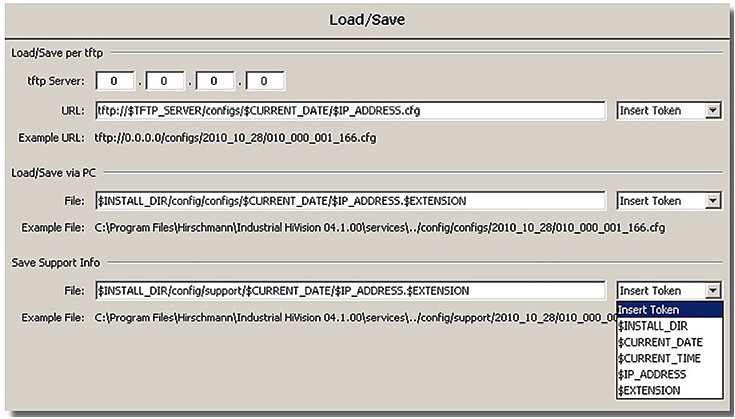
Mnohé z těchto systémů lze použít i pro hromadné aktualizace FirmWare.
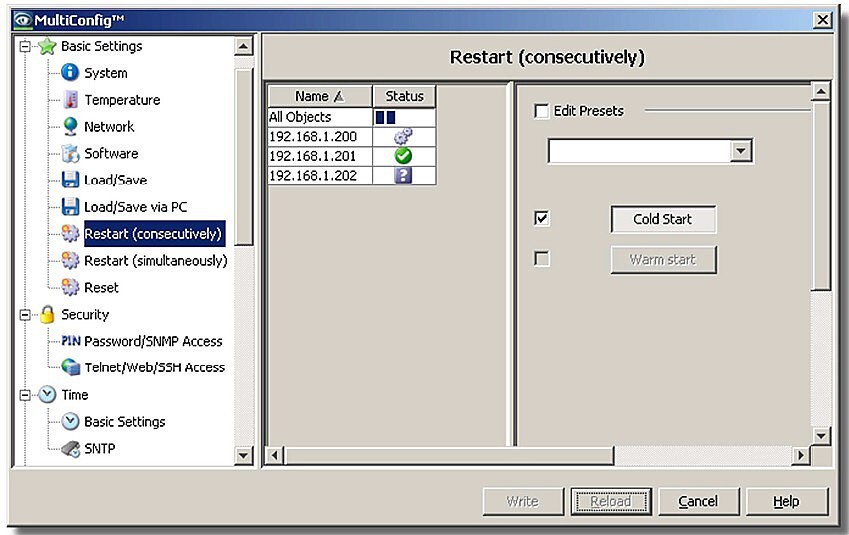
Jednou z nejdůležitějších funkcí pro KKI je postupný restart prvků. Samozřejmě, že není problém restartovat jeden prvek, skupinu nebo všechny současně. Takový postup není pro většinu případů vhodný. Došlo by dočasně ke ztrátě funkčnosti komunikačního systému. V těchto situacích je potřebné restartovat prvky postupně, aby byla zachována průchodnost sítě. Další prvek je vždy restartován až po náběhu předchozího. Operační diagnostika musí tento proces zvládat automatizovaně.
Mnohé systémy umožňují pro usnadnění správy a lepší dokumentaci sítě vytváření zákaznického popisu jednotlivých prvků.
Doplňování a integrace prvků
Systém operační diagnostiky musí také umožnit doplnění a integraci prvků i zařízení, které neobsahuje jeho databáze. Uživatel sám rozhoduje, které parametry je potřebné monitorovat a zobrazovat. Měla-by pracovat v základním mode, expert mode i v testovacím mode.
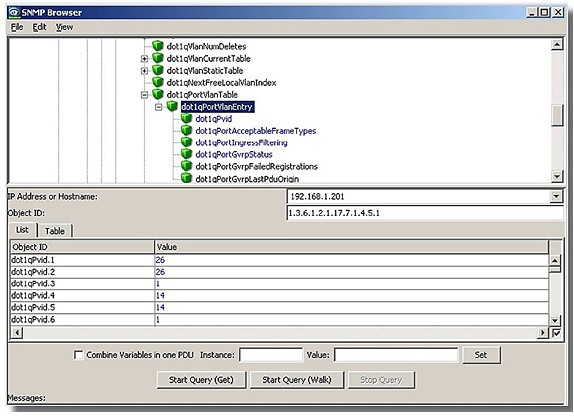
U prvků ze své databáze pozná systém jednotlivé prvky zařazené do sítě automaticky. U produkce jiných výrobců pouze v případě, že dodrží požadované specifikace v MNG prvku. Pokud tomu tak není, je prvku potřebné přiřadit příslušný soubor z databáze MIB (Management Information Base). K vyhledání příslušného prvku v databázi slouží MIB Browser. Ten bává součástí programu operační diagnostiky. Umožňuje snadno vyhledat prvky a jejich vlastnosti i proměnné, které hledáte. Má většinou i testovací režim příslušné proměnné (zařízení, komunikační spoj, nastavení, konfigurace, vlastnosti) před zavedením do systému a umožňuje popis pro každou proměnnou.
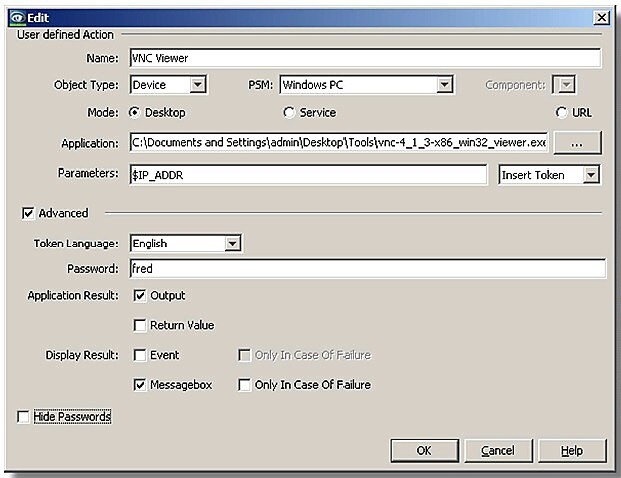
Uživatelská menu
Pro usnadnění obsluhy systému je vodná možnost vytváření uživatelsky definovaného MENU. V něm může správce definovat jednotlivé akce, spouštět externí aplikace nebo skripty. Výhodou je dostupnost všech aplikací z jednoho grafického rozhraní.
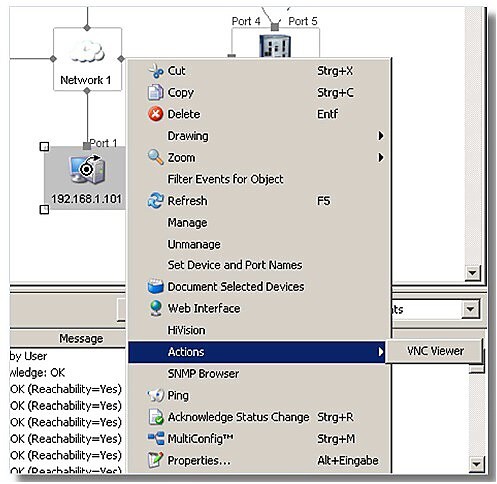
Automatické spouštění procesů
Za nezbytnou součást systému operační diagnostiky považuji nástroj, který nazvěme Scheduler. Ten umožňuje automatické spouštění úloh a procesů v předem určených časech a bez nutnosti manuálních zásahů operátorů. Mezi typické úlohy patří zapnutí/vypnutí PoE, blokování/odblokování portů a jiné úlohy, které se cyklicky opakují v definovatelných časech.
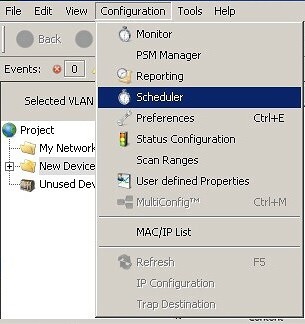
Provozní monitoring
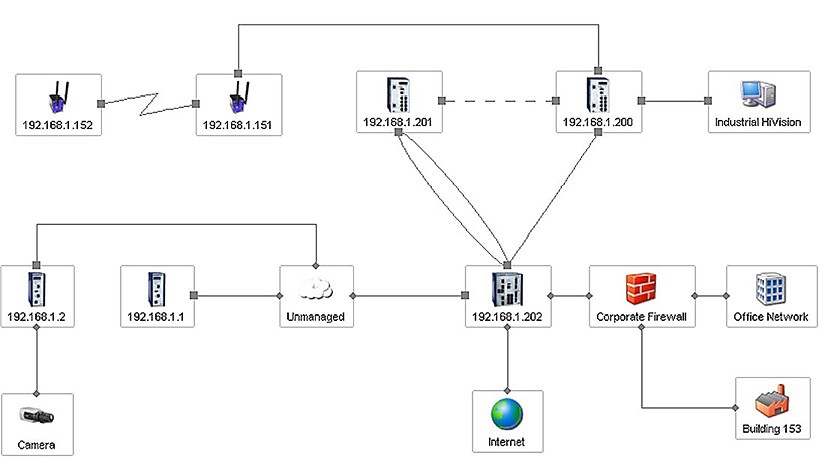
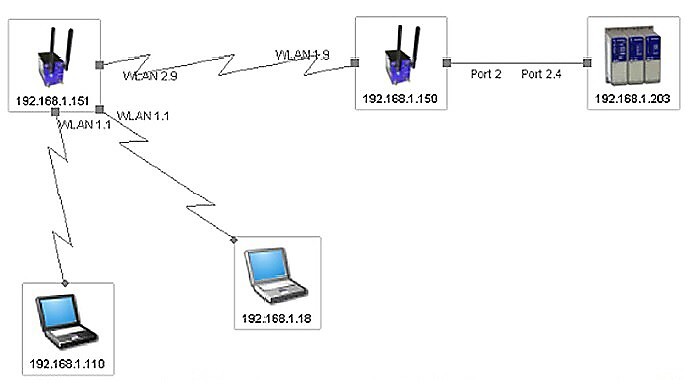
Systém musí soustavně monitorovat všechny komunikační linky a všechna definovaná zařízení v síti. Záměrně říkám definovaná, protože z celku můžeme některá zařízení vyloučit z monitoringu. Neustále sleduje jejich správnou funkčnost a zachování nastavených parametrů i nepovolenou změnu konfigurace. Zobrazení chybových stavů je v případě hierarchického uspořádání přeneseno i do nejvyšší úrovně.
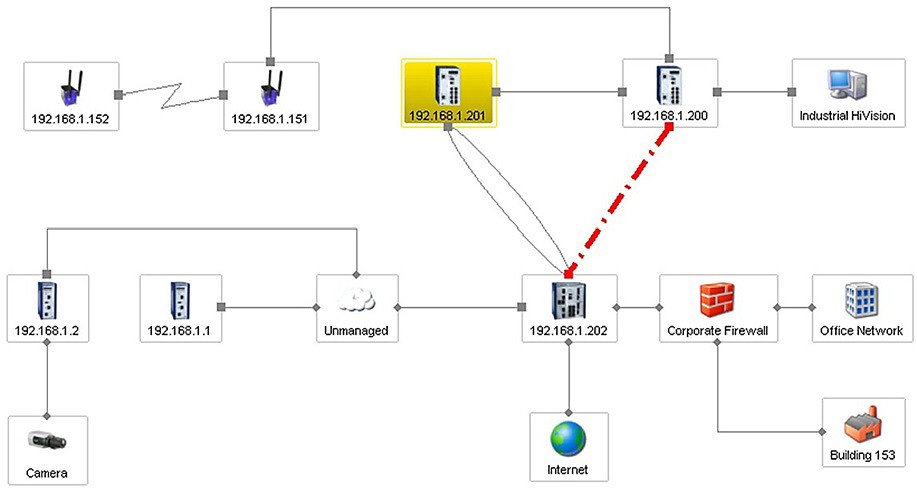
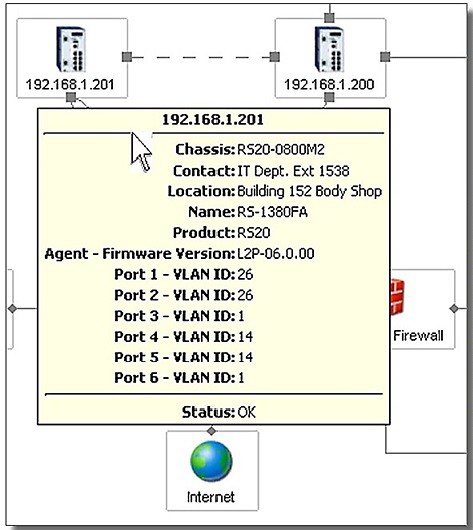
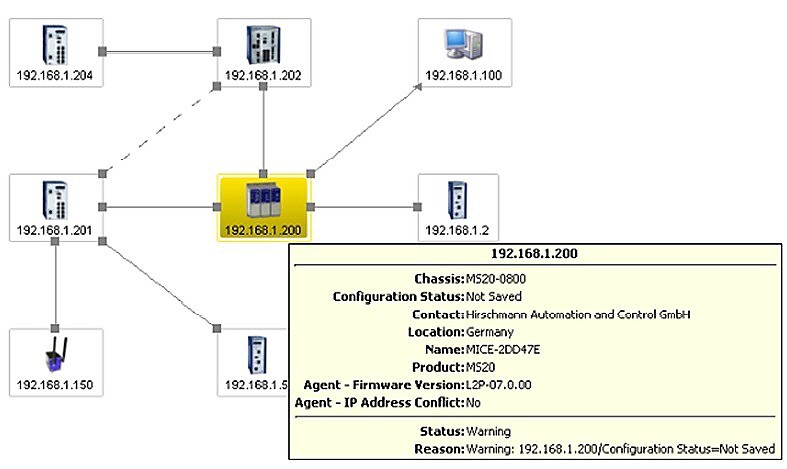
Na předcházejícím obrázku je červeně, tučně a čerchovaně zvýrazněná linka, která vypadla z provozu mezi uzly s IP adresou 192.168.1.200 a 192.168.1.202. Samozřejmě, tato musí být okamžitě zanesena do souboru historie událostí včetně času, kdy k výpadku linky došlo. Po registraci chyby systém okamžitě rozesílá varovná hlášení. Ta si vysvětlíme později.
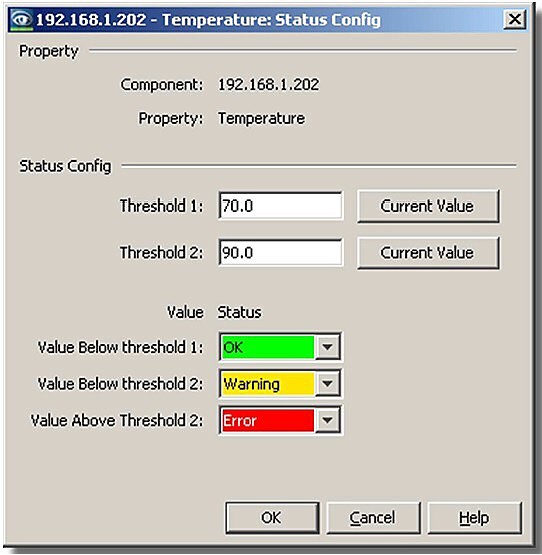
Správce systému operační diagnostiky musí mít možnost pro všechny prvky v síti nastavit prahové hodnoty pro hlášení, rozlišit stavy OK, Warning, Error. Může změnit i způsob zobrazení stavu, přizpůsobit barvy, symboly, zvýraznit blikáním atd. I toto nastavení lze řešit globálně. Mezi další sledované hodnoty (mimo chybové stavy) patří úroveň zatížení linek sítě a využití šířky pásma, teploty jednotlivých prvků nebo počty vadných rámců při přenosu. Následující obrázek je příkladem nastavení prahových teplot uzlu. Stav OK – zeleně, stav Warning při překročení 70°C – žlutě a stav Error při dosažení 90°C – červeně. Překročení obou hodnot je ihned zaznačeno do historie a ihned jsou vydána varovná hlášení.
Stejným způsobem by měl ohlásit u WiFi sítě pokles úrovně signálu nebo jeho ztrátu. Při poklesu úrovně pod prahovou hodnotu je spoj zobrazen žlutě, při ztrátě signálu červeně.

Formou varování upozornit i na stav, kdy byla v některém prvku změněna konfigurace a nebyla uložena do trvalé paměti. Při výpadku napájení by došlo ke ztrátě této nové konfigurace. V okamžiku, kdy je nová konfigurace uložena, je tato změna zaznačena do souboru historie.
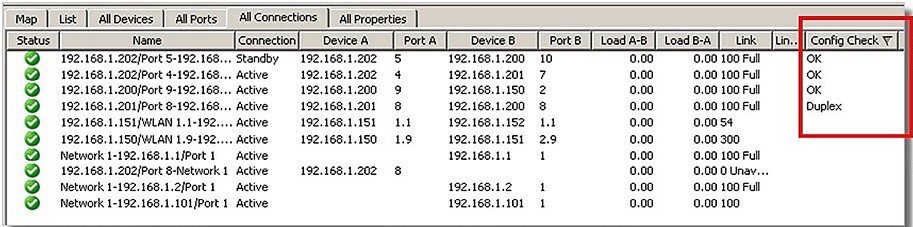
Součástí provozního režimu by mělo být i komplexní zobrazení informací o všech prvcích, portech i spojích. Zobrazení může být i včetně výrobního čísla, verze Firmware, MAC adresy, protokolu redundance, teploty i využití šířky pásma

případně i detekce neshody duplexních režimů celé sítě.
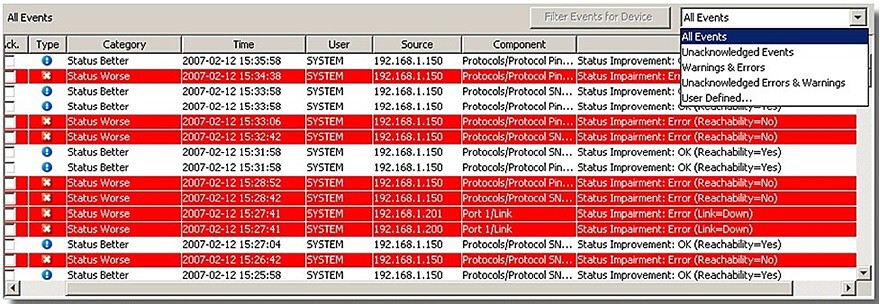
Protokoly události (Event Logs) a varovné zprávy (Alarms)
Tato část patří mezi hlavní důvody, proč vlastně takové automatizované systémy používáme.
Protokoly událostí nám umožňují kdykoliv zpětně dohledat co a kdy se stalo, jaká na to byla reakce, kdy byla porucha odstraněna atd. Historii událostí můžeme vytisknout a hlavně archivovat do externích souborů. To je velmi důležité pro zpětné dohledání problémů při vzniku kolizních situací.
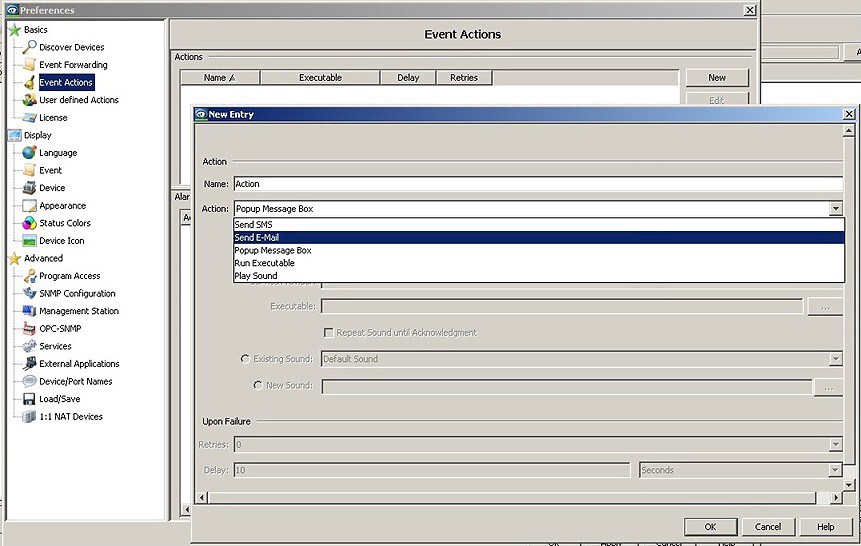
Nejdůležitějším důvodem použití operační diagnostiky je automatizované rozesílání varovných a poplachových zpráv o všech zařízeních i komunikačních linkách celé sítě. Monitorovaná síť může být značně rozsáhlá. Můžeme monitorovat například plošnou rozvodnou síť el. energie nebo plynu. Z toho důvodu je potřebný i variabilní a flexibilní systém zasílání varovných zpráv. Systém musí umožnit definovat příjemce (skupiny příjemců) zprávy až po úroveň každého zařízení a linky. Můžeme tedy určit nejen příjemce nebo jejich skupinu, ale pro každého i způsob předání zprávy (e-mail, SMS, sítová zpráva nebo jejich kombinace) a její obsah. To je velmi důležité rychlé informování příslušného servisního technika a operativní odstranění závady. Na základě vyvolaného alarmu lze dokonce spustit externí programy, které mohou automaticky řešit např. minimalizaci škody uzavřením ventilů plynovodu apod.
Správce systému musí mít možnost nastavení tzv. prahových hodnot parametrů pro všechny prvky i linky systému. To umožňuje rychlé odhalení problémů již v prvopočátku. Například upozornění na nezvykle velkou zátěž linky říká, že je něco nezdravého v tomto království.
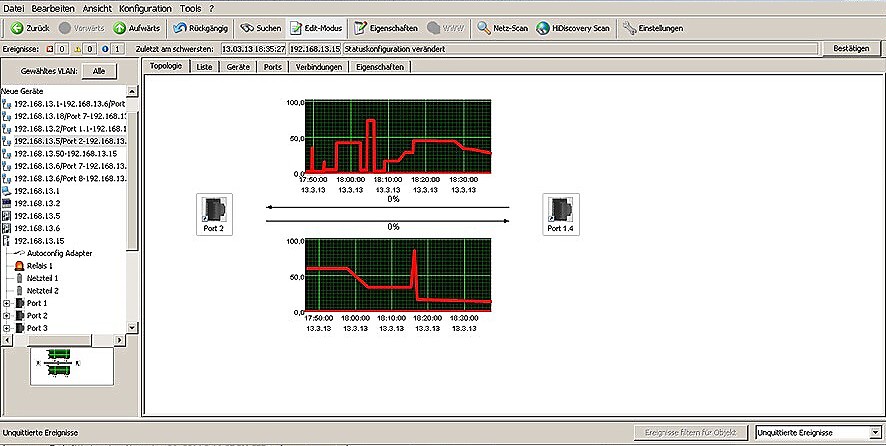
Mimo již popsané protokolování událostí a vydávání varovných zpráv by mělo být monitorováno i zatížení sítě a doba odezvy jednotlivých zařízení. V případě překročení nastavených limitů zátěže jednotlivých linek opět zasílá určeným adresátům varovná hlášení.
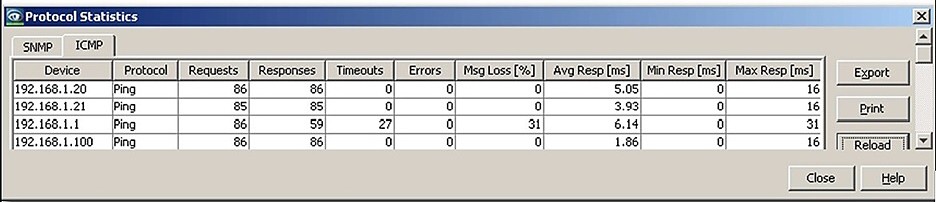
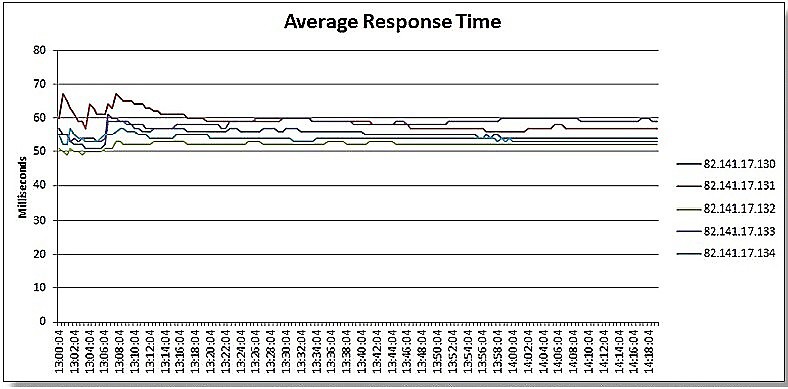
Integrace do systémů SCADA
Systém operační diagnostiky by neměl být závislý na operačním systému serveru nebo PC. To znamená, že musí být k dispozici pro všechna použitelná prostředí, ve kterých bude fungovat SCADA. Na použitém operačním systému závisí i způsob integrace do prostředí SCADA. Není tedy v možnostech této kapitoly představit jednotlivé varianty. Podstatné je, že producenti systémů operační diagnostiky mají pro jednotlivé OS nástroje integrace do SCADA systémů.
Výsledkem je stav, že pokud je v KKI vše bez závad, nemusí v reálném provozu uživatel – operátor systému SCADA na svém pracovišti vůbec registrovat, že nějaký monitorovací systém hlídá síť i koncová zařízení. Monitoring se ozve až v okamžiku spuštění varování nebo alarmu. Ve stavu bez poruch operátor sleduje pouze vlastní řízený proces.
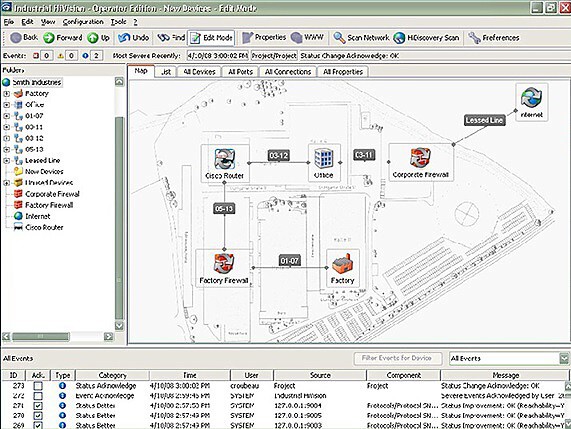
A závěrem malý bonus
U špičkových systémů operační diagnostiky existuje možnost doplnění hodnot MTBF a MTTR do databáze jednotlivých prvků. Systém bude nadále sám hlídat dostupnost jednotlivých zařízení. To je důležité pro plánování údržby a obnovy včetně včasného zajištění náhradních dílů nebo celých zařízení.