Protokoly redundance
Protokoly redundance na L2
V případě systémů kritické komunikační infrastruktury je jedním z nejdůležitějších technických opatření redundance komunikačních linek případně redundance částí nebo i celku vlastní komunikační infrastruktury. Ta je nejchoulostivější a nejzranitelnější částí monitorovaného nebo řízeného systému. Z pohledu celkového systému vykazuje největší chybovost a poruchovost.
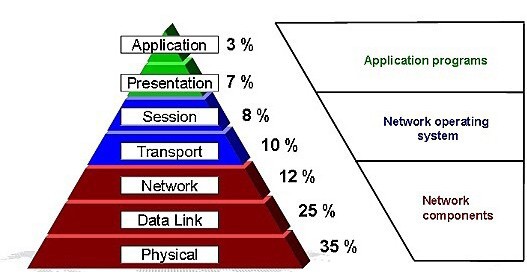
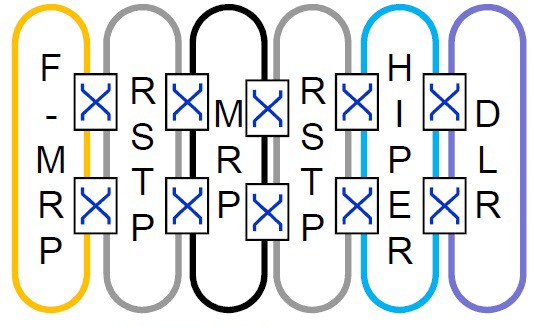
Následující obrázek představuje podíl jednotlivých vrstev OSI modelu na řešení redundance.
Agregace linek
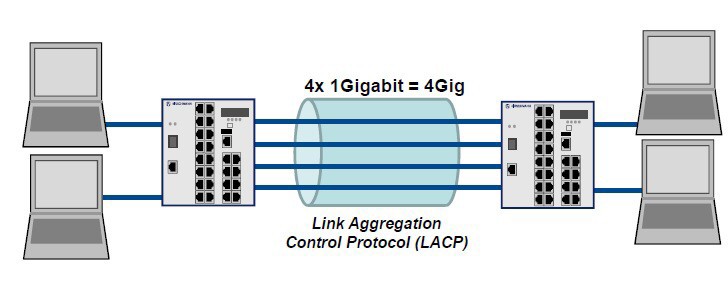
LACP (Link Aggregation Control Protocol – IEEE 802.3ad) je síťový protokol pro dynamické sloučení fyzických linek síťového připojení do jednoho komunikačního kanálu.
K čemu slouží agregace linek?
Důvody pro použití LA jsou dva:
Prvním je řízení přímých redundantních spojů (s vyloučením nežádoucích smyček).
Pokud nebude vícenásobné spojení mezi prvky řízeno pomocí LACP nebo jiným protokolem stejné funkce, dojde k tzv. broadcastové smršti (broadcast storm). Ta obvykle zahltí celou síť. Tento problém jsem schopni ošetřit i jinými metodami, které budeme vysvětlovat v dalších kapitolách.
Druhým a hlavním důvodem je zvětšení šířky pásma komunikačního kanálu.
Sloučením minimálně dvou linek do jednoho agregovaného komunikačního kanálu (Trunk) dosáhneme větší šířky pásma pro přenos. Celková šířka pásma agregovaného kanálu je rovna součtu šířek pásma všech linek, které se podílí na této agregaci. Rozložení zatížení mezi jednotlivé linky Trunku se provádí automaticky. Trunk vznikne nakonfigurováním agregace alespoň dvou existujících paralelně zapojených redundantních linek mezi dvěma zařízeními do jednoho logického spojení. Většinou můžete do Trunku agregací spojit 4 (v některých případech až 8) linek. Při konfiguraci agregace se přiřazuje zvolená skupina fyzických portů Switche virtuálnímu portu. Trunk může být vytvořen z TP linek, FO linek nebo i jejich vzájemné kombinace. Počet Trunků je většinou omezen pouze počtem fyzických portů Switche.
Agregaci linek můžeme použít nejen v jednoduchých strukturách (viz předcházející obr.), ale i ve strukturách složitějších. Příkladem budiž hierarchická hvězda TREE – strom.
nebo kruh (Ring).
Skupina protokolů STP
STP – Spanning Tree Protocol
RSTP – Rapid Spanning Tree Protocol
MSTP – Multiple Spanning Tree Protocol
atd. nějaké STP
O těchto protokolech již bylo na internetu napsáno tolik, že nemá smysl je popisovat. Pouze velmi stručně shrneme základní vlastnosti:
– určeny k řízení nepřímé i přímé redundance (nikoliv agregace linek)
– jsou nezávislé na topologii (mimořádná výhoda)
– mají dlouhou dobu rekonfigurace sítě STP – 30sec., RSTP – 2sec. – tím jsou pro KKI prakticky nepoužitelné
– u RSTP díky zkrácení času rekonfigurace vzniká riziko, že rámce zaslané během fáze rekonfigurace RSTP topologie by mohly být zkopírovány a/nebo dorazí k příjemci v nesprávném pořadí.
Pokud je to pro použitý přenosový protokol nepřijatelné, musíme použít pomalejší STP nebo zvolit jinou metodu řízení záložních tras. Nazvěme tento stav riziko RSTP.
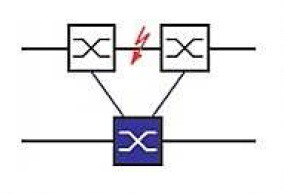
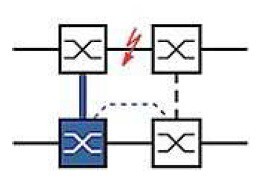
Link Backup
Toto řešení umožňuje řízení redundance mezi třemi prvky. Na řídícím Switchi (A u prvního obrázku a E u druhého) stanovíme, který port je primární a který je jeho partnerem v Backup stavu. Počet takových dvojic je dán typem konkrétního Switche. Doba rekonfigurace je dle typu menší než 1s. Způsob využití dostatečně demonstrují oba následující obrázky
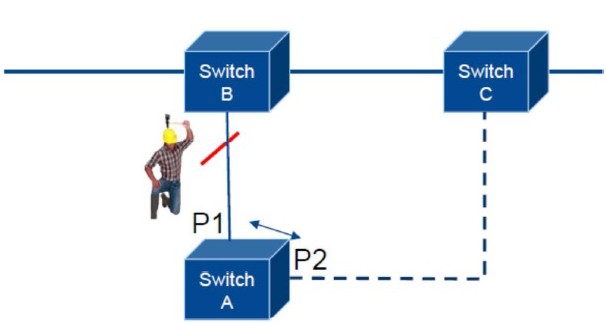
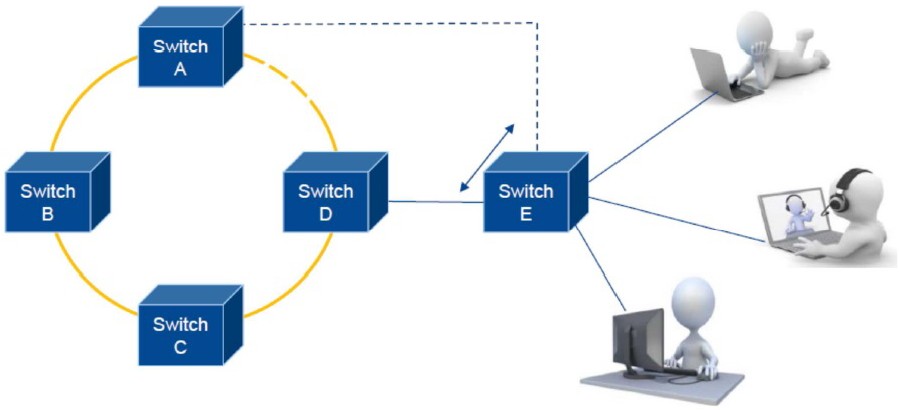
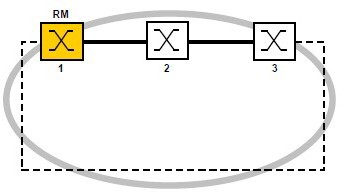
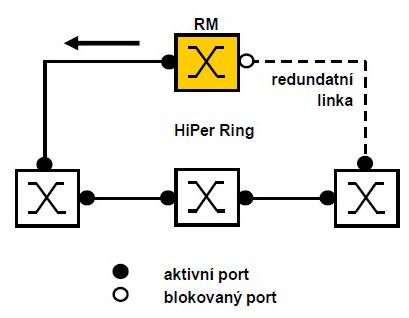
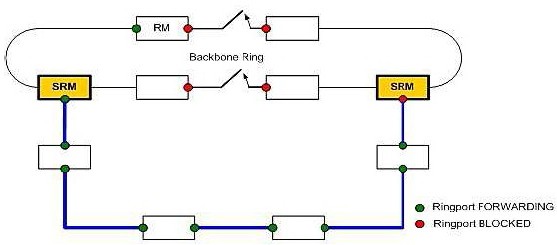
Koncepce kruhových sítí řízených Ring Managerem
Koncept redundance v kruhu umožňuje konstrukci sítě s vysokou dostupností prostředků síťové struktury. S pomocí funkce RM (Ring Managera) jsou oba konce páteřní lineární struktury propojeny na redundantní kruh. RM kruhu udržuje redundantní linku uzavřenou, pokud je struktura kruhu neporušená. Pokud se některý segment stane nefunkční, RM okamžitě otevře redundantní linku a lineární struktura je opět funkční.
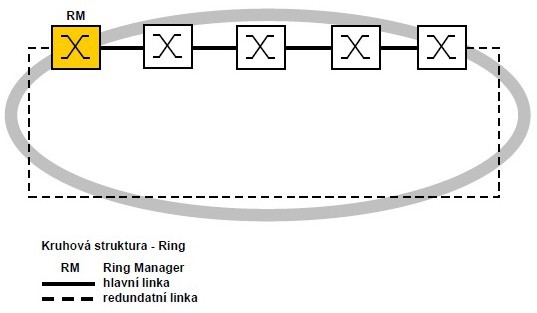
Mnozí si kladou otázku: „Co se stane, když vypadne RM? Kdo bude dál řídit kruh?“
Odpověď je velmi jednoduchá. Nestane se vůbec nic. Poruchou kteréhokoliv uzlu nebo výpadkem kterékoliv linky se mění struktura kruhu na lineární. Tudíž tam žádné další řízení není potřebné.
Nedostatkem tohoto nového stavu je skutečnost, že první porucha vytvořila strukturu bez redundance. I této situaci jsme schopni dalšími prostředky zabránit. Pomocí prvku Bypass jsme schopni nefunkční uzel přemostit a redundance v kruhu zůstane zachována.
Stav před poruchou uzlu.
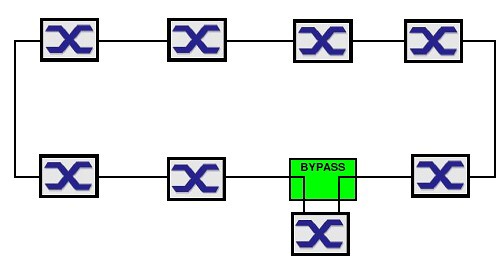
Stav při poruše uzlu.
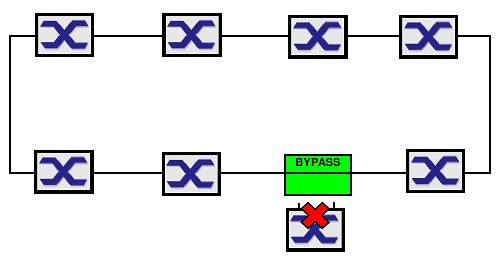
Redundance kruhu tedy zůstane zachována. Nefunkční bude pouze přemostěný uzel, který je ve stavu poruchy. Bypass můžeme použít u všech uzlů v kruhu s výjimkou RM. Ten naopak nesmíme přemostit nikdy. Pokud by došlo k poruše RM a byl následně přemostěn Bypassem, kruh by se uzavřel, ale nikdo by ho neřídil. Důsledek – broadcast storm.
Bypass pro metalické vedení se zabudován přímo v příslušných modelech Switchů.
Bypass pro optická vedení je samostatným prvkem, který se připojuje mezi kruh a Switch. Princip zapojení je na následujícím obrázku.
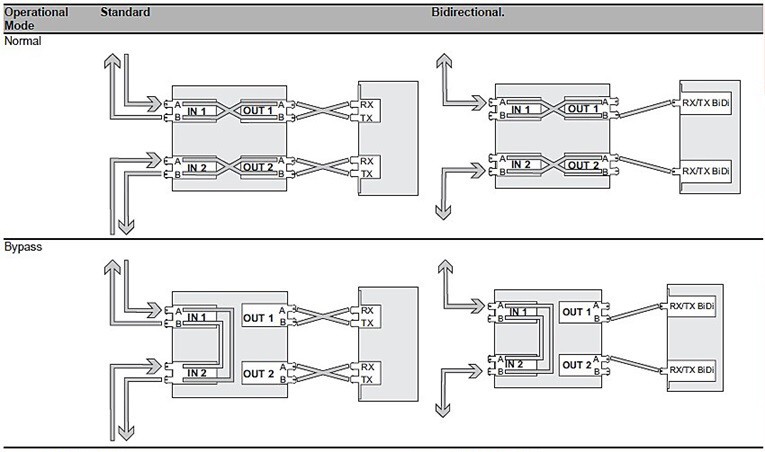
Tento externí Bypass se přepne ve stavu, kdy ztratí napájení. To znamená, že jeho funkce je na první pohled omezena pouze závislost na napájení uzlu. Switche pro KKI mají programovatelný kontakt a my můžeme Bypass napájet přes něj. V tu chvíli jsme schopni nadefinovat, při kterých typech poruch se má Switch přemostit.
MRP – Media Redundancy Protocol
MRP je jedním z prvních protokolů určených pro řízení redundance v kritických průmyslových aplikacích. Byl vyvinut v roce 1998 a mezinárodním standardem se stal v březnu 2008. Je definován v normě IEC 62439-2, která popisuje průmyslové standardy pro vysokou dostupnost Ethernet sítí. MRP je určen pouze pro topologii Ring.
MRP umožňuje řídit kruhovou síť, která má až 50 zařízení (Switche nebo jiná MRP zařízení, např. řídící jednotky apod.), a zaručuje plně deterministické chování při rekonfigurace kruhu na záložní trasu. Časový limit pro rekonfigurace lze nastavit na 500ms nebo 200ms. Typická doba přepnutí na záložní trasu je obvykle poloviční až čtvrtinová. U nastavení 200ms to je mezi 50 a 60ms. MRP je protokol linkové vrstvy. Používá podobné mechanismy jako RTSP, např. mazání záznamů v FDB, nastavení portů do stavu blocking, forwarding atd. Všechna zařízení v kruhu musí podporovat MRP protokol. Jedno ze zařízení v MRP kruhu je definováno jako Media Redundancy Manager (MRM), ostatní jsou definována jako Media Redundancy Client (MRC). MRP pracuje na 2. vrstvě OSI modelu (linková vrstva) nad přístupem k MAC adresám.
MRP používá následující status portů:
Blocking
Disabled
Forwarding
non-connected
Poznámka: při volbě doby rekonfigurace 200ms vzniká riziko jako u RSTP. Pokud je to pro aplikaci nepřijatelné, musíme nastavit dobu rekonfigurace na 500ms.
Každý MRP uzel vyžaduje Switch se dvěma Ring-porty, které jsou zapojeny do kruhu. Jeden z těchto Switchů má funkci Media Redundancy Manager (MRM). MRM monitoruje i řídí kruh a reaguje na případné selhání sítě. Monitoring provádí tím způsobem, že posílá Ethernet redundancy test frames MRP DU (testovací rámce) přes jeden ring-port a na druhém kontroluje jejich přijetí. Následně proces opakuje v opačném směru. MRP DU je funkční obdoba RSTP BPDU.
Za normálního stavu (bez závad) je jeden z těchto portů ve stavu Blocking, tj. přijímá pouze MRP DU. Na logické úrovni převádí fyzický kruh na lineární strukturu pro běžný síťový provoz. Tím zabraňuje vzniku smyček.
V případě selhání přenosu (MRM neobdrží vyslané testovací rámce např. v důsledku selhání zařízení nebo vadné trasy), MRM otevře dříve blokovaný ring-port pro normální provoz. Tím budou všechna zařízení dostupná přes sekundární síťovou cestu.
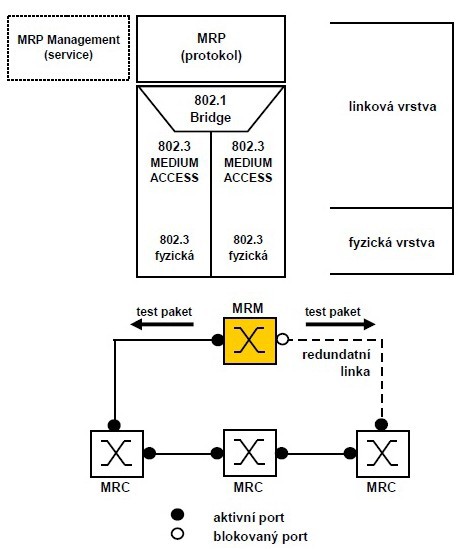
Všechny ostatní uzly v kruhu mají úlohu Media Redundancy Client (MRC). MRC přeposílá testovací rámce od MRM z jednoho svého ring-portu na druhý. Také reaguje na jakékoliv přijaté rámce rekonfigurace (změna topologie) z MRM, detekuje změny stavu svých portů a oznamuje tuto skutečnost MRM. Pokud nastane takový stav, že zpráva o změně od MRC dojde na MRM dříve než bylo detekováno selhání Ringu testovacím rámcem, je provedena detekce na základě této zprávy od MRC. Tím je zajištěno, že přechod komunikace MRM z primární na sekundární cestu proběhne vždy v nejkratším možném čase
Příklad nastavení RM v síti MRP Ring
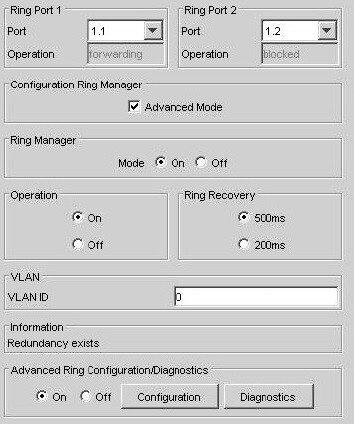
Ring-porty zařazeny do kruhu jsou 1.1 a 1.2. Systém zvolil za aktivní ten s nižším číslem, tedy 1.1. Port 1.2 je ve stavu blocked. Čas pro rekonfigurace byl zvolen 500ms. To, že se jedná o RM je určenou volbou Ring Manager: Mode: On. Ostatní Switche v kruhu musí mít toto nastavení na Off.
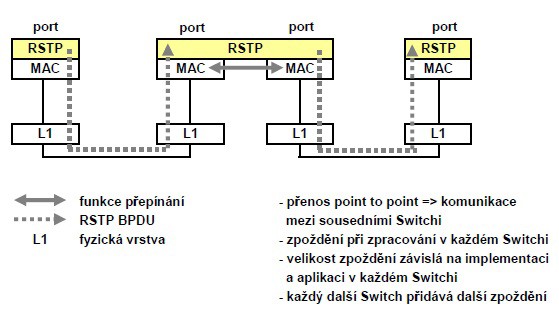
Srovnání principu práce RSTP a MRP.
RSTP posílá BPDU z uzlu do uzlu (Switche). Jde tedy o komunikaci typu point to point. V každém uzlu je BPDU analyzováno a případně provedeny dle obsahu potřebné operace. Tím vzniká v každém uzlu zpoždění, které závisí na rychlosti procesoru příslušného Switche, implementaci RSTP, na dalších současně zpracovávaných protokolech atd. S počtem Switchů v síti narůstá úměrně i zpoždění.
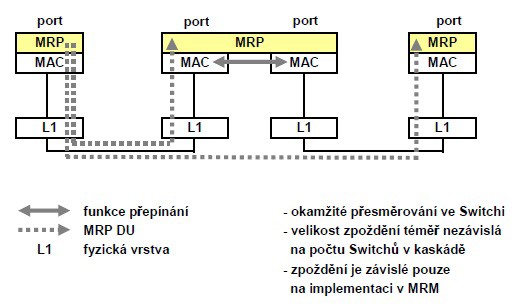
V případě MRP jsou testovací rámce ihned přeposílány na druhý Ring-port bez jakéhokoliv zpoždění vytvořeného analýzou procesoru. Zpoždění na Switchi odpovídá pouze zpoždění průchodu několika elektronickými obvody (řádově v ns). Proto celkové zpoždění v kruhu nemá natolik strmou závislost na počtu Switchů jako u RSTP.
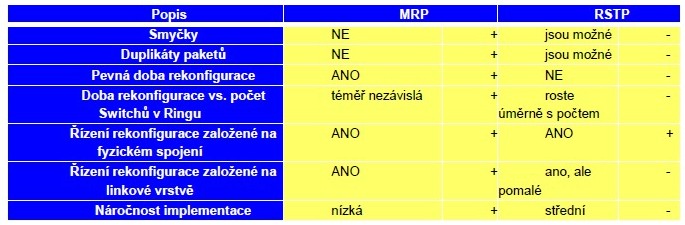
Srovnání vlastností RSTP a MRP.
Kombinace MRP a RSTP
V některých případech musíme použít kombinaci MRP protokolu a RSTP. Důvodem může být nejen ta skutečnost, že některá zařízení nemusí podporovat MRP protokol, ale i potřeba odlišné topologie než je Ring. Výhodou MRP protokolu je to, že může pracovat v režimu kompatibility s RSTP.
FMRP – Fast Media Redundancy Protocol
FMRP je mladší a zrychlenou verzí MRP. Počet uzlů 50 zůstal zachován při zrychlení doby rekonfigurace na 30ms.
HR – HIPER Ring (High Performance Ring)
Výkonnější verzí řízení redundance v kruhové síti je HiPer Ring. HR umožňuje řídit v kruhové síti max. 100 Switchů a zaručuje plně deterministické chování při rekonfigurace kruhu na záložní trasu. Délka kruhu může být až 3 000km a max. povolená vzdálenost dvou sousedních Switchů je 100km. Maximální přípustná doba rekonfigurace pro 100 Switchů a max. délku kruhu je 500ms. Typická doba přepnutí na záložní trasu při uvedené velikosti sítě je 250 až 270ms.
Princip funkce je částečně obdobný jako u MRP. Ring Manager (RM) vysílá každých 20ms testovací rámec nazývaný „watchdog“(obdoba MRP DU). Tím testuje integritu kruhu. Jeho druhý Ring-port, který je v zablokovaném stavu přijímá pouze tyto rámce. V případě, že RM neobdrží ve stanoveném čase testovací rámec, okamžitě aktivuje blokovaný port a tím i redundantní linku. Okamžitě rozesílá informace o novém připojení všech Switchů tak, aby tabulka MAC adres byla všude přepsána najednou. Po opravě poškozené linky se obnoví komunikace po původní trase.
U HR tedy opět definujeme Switch s funkcí Ring Manager (RM). Tomu při konfiguraci nastavíme operační mód RM do „On“. Všem ostatním jej ponecháme ve stavu „Off“. U všech Switchů musíme také určit, které porty budou zapojeny v kruhu – Ring-porty. RM většinou volí Ring-port s nižším číslem jako aktivní a Ring-port s vyšším číslem blokuje. Na rozdíl od MRP je testovací rámec vysílán pouze jedním směrem (důvodem je úspora času).
Proces detekce chyby a přechodu na záložní trasu lze urychlit nastavením volby Ring Recovery: Accelerated. Switche v tomto režimu samy posílají služební zprávu do RM o ztrátě konektivity na druhém Ring-portu. V tomto případě je nutné uvedený režim nastavit na všech Switchích v kruhu.
Rozdíly HR oproti MRP:
HR posílá testovací rámce pouze jedním směrem
RM HR po obnově konektivity nefunkční linky vždy aktivuje původní Ring-port
vzhledem k výrazně rychlejšímu časování HR není možná kompatibilita s RSTP
Výhody HR oproti MRP:
výrazně rychlejší rekonfigurace na záložní trasu
výrazně větší počet Switchů v kruhu (až 100)
možnost agregace linek mezi jednotlivými Switchi do Trunku (pouze některé typy Switchů)
FHR – FAST HIPER Ring (Fast High Performance Ring)
Pro mimořádně náročné aplikace (hlavně energetika) byla vyvinuta rychlá varianta řízení redundance v kruhu, tzv. Fast HiPer Ring. Princip je shodný s HR. Zvýšil se pouze počet Switchů v kruhu na 200 a zkrátila se doba rekonfigurace sítě na max. 50ms. Typická doba rekonfigurace při plném počtu Switchů je 40ms, pro 100 Switchů 25ms a pro 10 Switchů 5ms. Upozorňuji, že tuto FHR umí opět pouze určitá skupina Switchů s HR.
Redundance v kruhových sítích
Zásada: v jedné síti topologie Ring můžeme použít vždy pouze jedinou variantu řízení – STP, RSTP, MRP, HR nebo FHR. Nelze je v jednom kruhu kombinovat. V každém kruhu může být pouze jeden Ring Manager.
Pokud máme více kruhových sítí s odlišným způsobem řízení, je nutné zvolit správné prostředky pro jejich propojení.
FuseNet
V reálném životě mnohdy nevystačíme s jedinou kruhovou strukturou v síti. Platí to hlavně v případech, kdy kruh není pouze páteřním vedením, ale obsahuje i koncová řídící zařízení. Následující varianty ukazují, jak lze řešit propojení více kruhů nebo přímo vytvářet struktury s více kruhy.
Pro spojování (a rozšiřování) kruhových sítí s rozdílným způsobem řízení jsou určeny prostředky FuseNet. Ten nabízí tři základní řešení:
– SR – SubRing
– RNC – Ring Network Coupling (lze i pro spojení ring s jinou topologií)
– RCP – Redundant Coupling Protocol
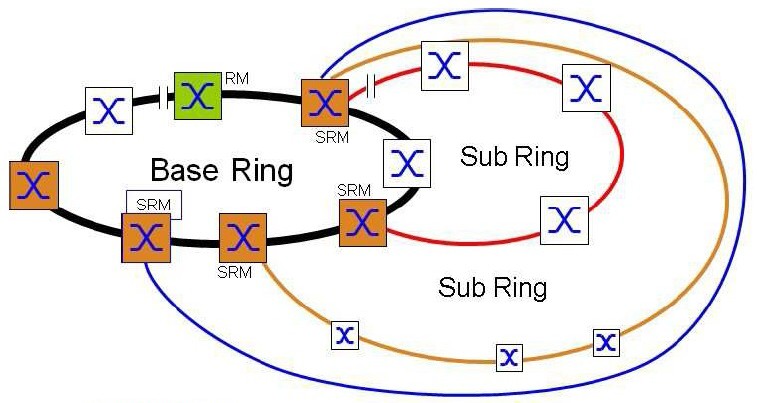
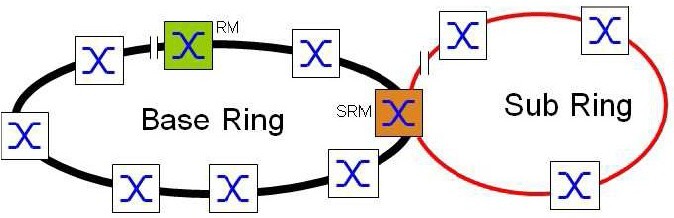
SubRing
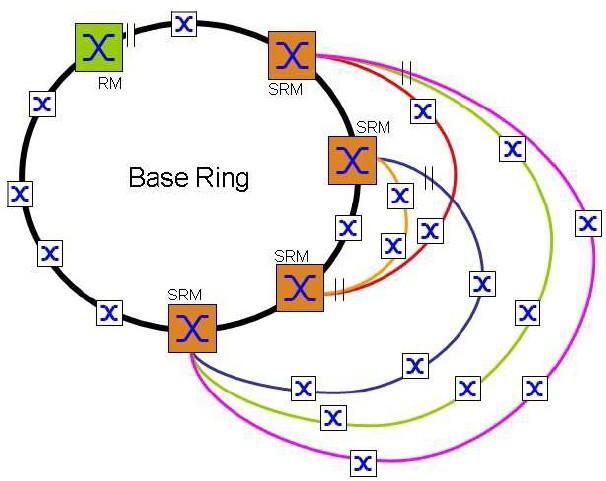
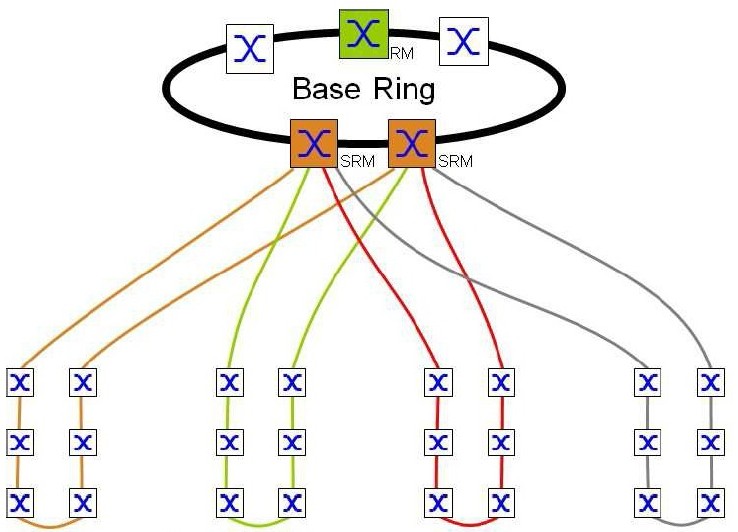
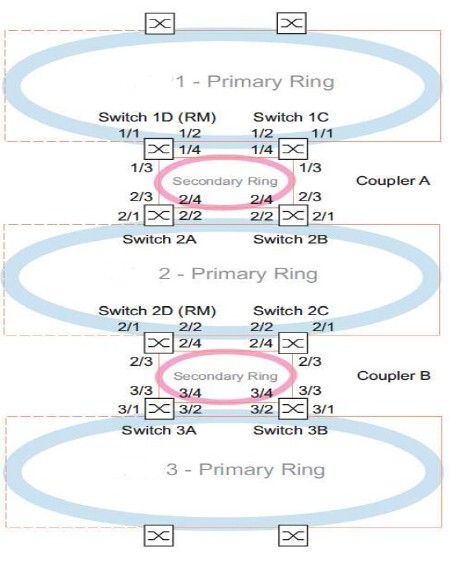
Jde o proprietární patentované řešení. Koncept SubRing umožňuje snadné rozšiřování základního Ringu o nové redundantní segmenty sítě. Tento proces je možné provádět za plného provozu základního kruhu a bez omezení provozu. Switche, které jsou zařazeny v základním kruhu a je přes ně připojen SubRing, plní úlohu SubRing Managera (SRM). Napojení SubRingů umí opět pouze určitá skupina Switchů. Jeden SRM může obsluhovat napojení 4, 8, 12, 16 nebo 20 SubRingů (dle typu Switche – viz tabulka funkcí v závěru této sekce). Každý SubRing se může skládat z max. 200 uzlů přičemž SRM umístěné v základním Ringu se mezi ně nepočítají.
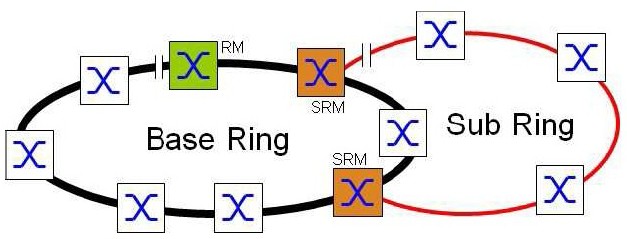
Zařízení zařazená do SubRingu musí umět pracovat s MRP protokolem, i když základní Ring pracuje nejen s MPR, ale s protokolem HR, FHR nebo DLR. Přepínací čas SubRingu na redundantní trasu je obvykle <100ms.
Mezi základní výhody koncepce SubRingu patří možnost velmi snadného rozšiřování struktury sítě a snadná integrace nových zařízení i celých sub-sítí, a to omezení provozu již funkčních částí sítě. Varianty možných topologií pokrývají prakticky veškeré potřeby reálných řešení Předcházející obrázek znázornil topologii s jedním SubRingem. Koncepce samozřejmě umožňuje k základnímu Ring připojení mnoha SubRingů. Jediným omezením je, že na každý Switch můžeme připojit pouze tolik SubRingů, kolik jich příslušný Switch umí. Počátky a konce SubRingů můžeme libovolně kombinovat mezi jednotlivými uzly základního Ring.
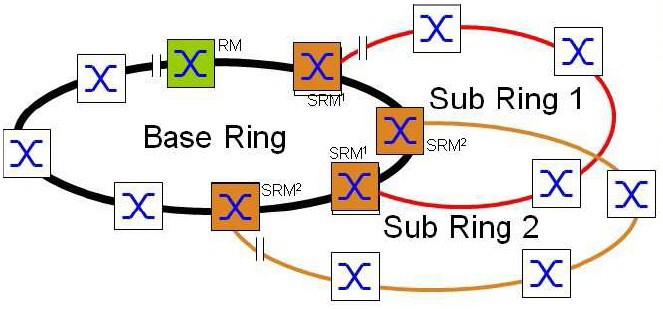
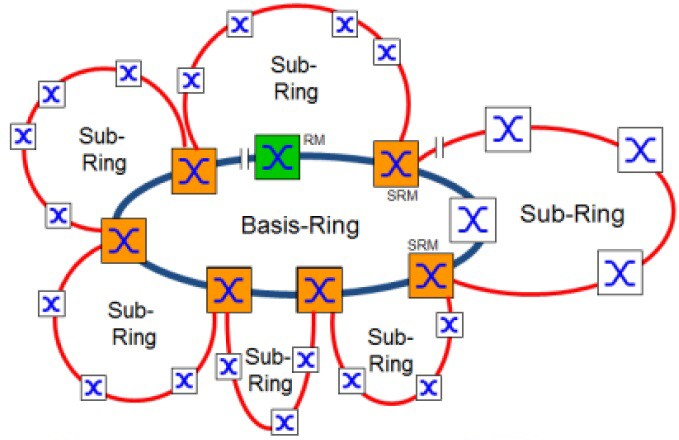
Existuje i možnost vytvoření SubRingu, který začíná i končí na stejném prvku základního Ringu. Z pohledu redundance je tato varianta ovšem nesmyslná. V případě poruchy tohoto Switche by nekomunikoval celý SubRing.
Zkoušeli jsme i kaskádovitě připojovat na SubRing další SubRingy a fungovalo to. Vývojovým oddělením nám bylo sděleno, že v této variantě by mohlo docházet ke kolizím synchronizace času při práci v RT.
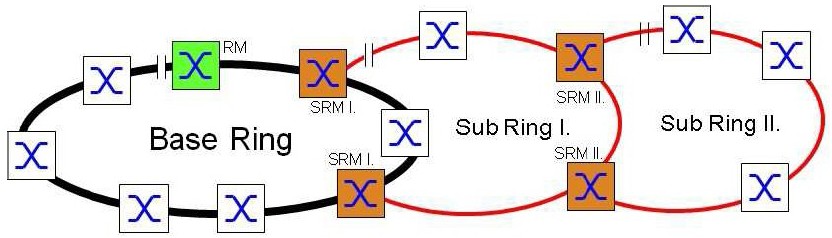
Princip funkce SubRing
Každý SubRing je do základního Ringu napojen konci do dvou Switchů. Jeden z těchto Switchů má funkci SRM – SubRing Manager, druhý na opačném konci má funkci RSRM -„Redundancy SubRing Manager. Výjimkou je zakončení na jednom Switchi, kde je aktivován SRM i RSRM. Sub Ring pracuje nezávisle na základním Ringu. Dokud SubRing pracuje (tj. je funkční konektivita mezi SRM a RSRM cestou SubRingu), je port RSRM směrem do SubRingu blokován. Ten se odblokuje při přerušení SubRingu.
SubRing nezajišťuje redundanci pro základní Ring. V případě dvojitého přerušení základního Ringu (viz násl. obr.), by vznikl problém v komunikaci mezi oběma částmi základního kruhu. SubRing tedy nepředstavuje rozšíření redundance, ale pouze rozšíření topologie. Pro základní Ring je jeho vlastní redundance tedy nezbytná.
RNC – Ring Network Coupling
Řešením pro spojení více kruhů je Ring Network Coupling – spojka kruhů. Princip představuje následující obrázek.
Spojení lze řešit třemi způsoby.
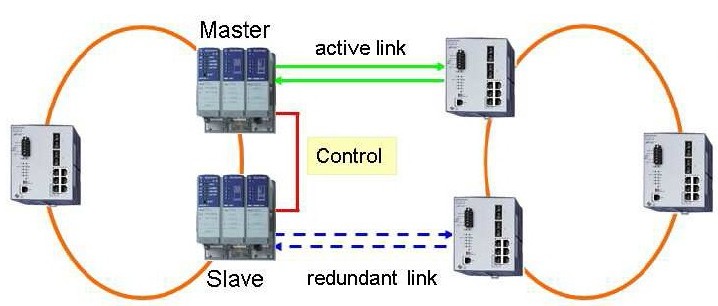
První variantou je spojení ze dvou portů jednoho Switche 1. základního kruhu na dva různé Switche druhého základního kruhu. Toto řešení má obdobný nedostatek jako u SubRingu varianta single SRM. V případě poruchy Switche s RC v 1. kruhu se stává spojení mezi kruhy nedostupným. Tato varianta řeší pouze výpadek linky nebo jednoho Switche s RC v druhém kruhu. Funkčně lze použít jako Link Backup.
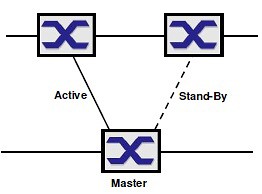
Druhou variantou je propojení obou kruhů ze samostatných Switchů o obou kruzích. V tom případě je jeden z nich řídící (Master) a druhý podřízený (Slave).
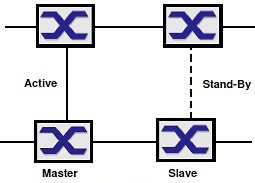
Ve třetí variantě je stejné propojení doplněno ještě o řídící linku mezi Switchem Master a Slave. Díky tomu není vlastní datová linka mezi oběma Switchi zatěžována služební komunikací.
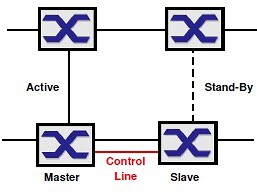
Ve všech případech je jedna linka aktivní a druhá (redundantní) je blokována. Ta se odblokuje až v případě výpadku aktivní linky. Po odstranění poruchy se status aktivace linek vrátí do původního stavu, tj. redundantní bude opět blokována. Maximální doba přepnutí je 500ms, typická doba 150ms.
Ukázka možností nastavení konfigurace.
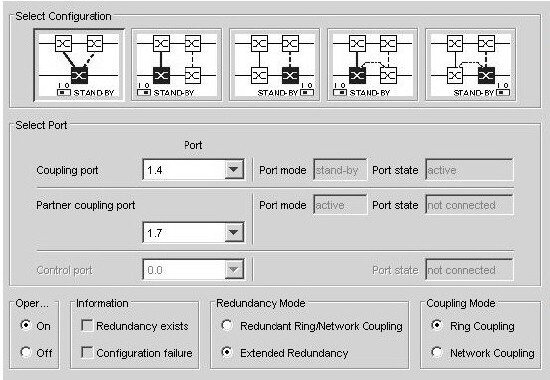
Při nastavení „Extended Redundancy“ RNC zajistí redundanci i pro základní kruh (obě linky couplingu jsou aktivní současně při přerušení kruhu). Při tomto nastavení může dojít během doby rekonfigurace ke stejnému problému, jako u RSTP.
RCP – Redundant Coupling Protocol
Třetí řešení pro spojování kruhů odstraňuje nedostatky kaskádového zapojení SR a rozšiřuje možnosti propojení o nezávislost na protokolu MRP (jako je u SR).
Z propojovaných kruhů musí umět RCP pouze Switche určené k jejich propojení. Struktury lze tedy rozšiřovat opět bez omezení provozu původních kruhů.
Pro vyrovnání rozdílů v časování vytváří protokol na rozhraní spoje virtuální sekundární kruhy. Proto jsou v každém primárním kruhu Switche propojeny dvěma linkami a Switche musí spolu sousedit.
Příkladem aplikace RCP může být síť ve vlakové soupravě.
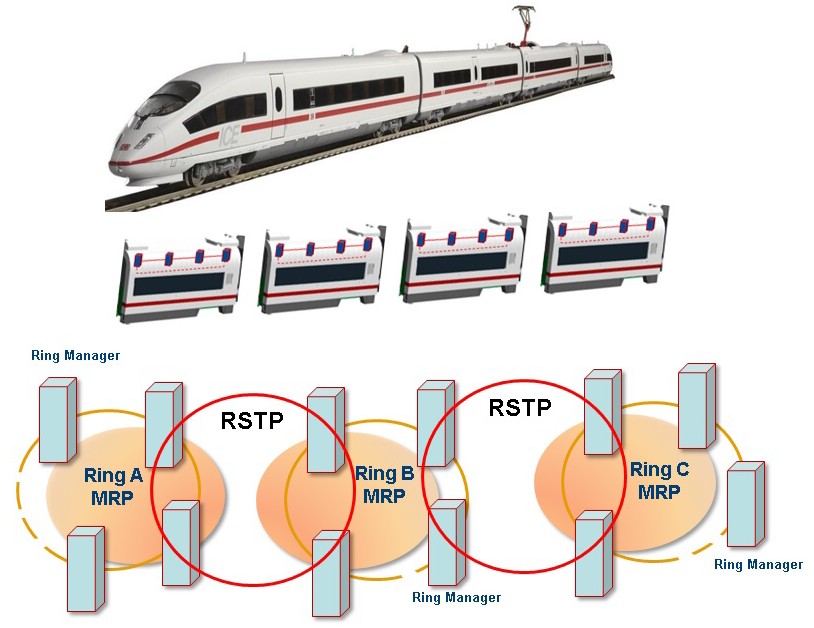
Samozřejmě, že toto řešení má velmi dobré využití i v mnoha jiných aplikacích.
Koncepce kruhových sítí s RM – závěrečné INFO
Mimo dříve popsané protokoly řízení kruhových topologií existuje mnoho dalších, často proprietárních řešení. Většinou mají označení „nějaký-ring“ a když je člověk do stane k testování, nestačí se divit. Na toto téma již zaznělo pár slov v úvodu části „Odolnost – aktivní prvky“. Existují dokonce i takoví exoti, kteří tvrdí, že jejich řešení řízení kruhové topologie s RM má nulovou dobu rekonfigurace.
Nezbývá než tuto část uzavřít citací dědečka Hříbečka: „kdybys nebyl medvědem, nestal by ses hlupákem“ nebo jak to bylo předsedo?
Koncepce kruhových sítí s nulovou dobou rekonfigurace
V reálném prostředí existují aplikace, pro které jsou doby rekonfigurace sítě na záložní trasu uvedené v předcházejících řešeních příliš dlouhé. Z tohoto důvodu byly vyvinuty dvě technologie, které mají tento čas nulový. Tomu, kdo používá ZSR (zdravý selský rozum), začne blikat v hlavě výstražná kontrolka. Jak může být čas na nějakou činnost nebo proces nulový? Jediná správná odpověď zní: tato činnost nebo proces neprobíhá. A to platí i pro náš případ. Vždy je to ovšem něco za něco. Princip těchto technologií spočívá ve vysílání duplikátů rámců do sítě. Redundance tedy probíhá již na úrovni přenosu informace.
První z těchto nich je HSR.
HSR – High Availability Seamless Redundancy
Zdroj: Kirrmann Hubert, Prof.Dr..: HSR-Fault tolerance in Ethernet networks IEC 62439-3, presentace na CIGRE 2012, Paříž
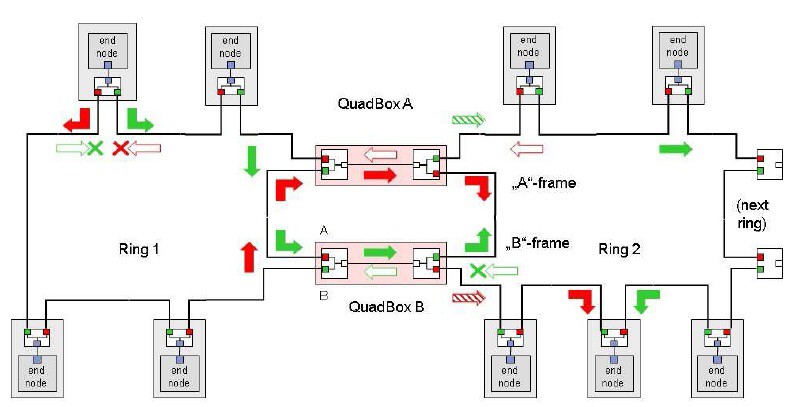
HSR je řešení určené pro redundanci výhradně v kruhu a umožňuje konstrukci sítě s vysokou dostupností všech prostředků síťové struktury s nulovou dobou rekonfigurace na záložní trasu. V kruhu jsou veškeré rámce posílány současně oběma směry. Každý uzel má dva porty, které mají stejnou MAC adresu i IP adresu.
Princip zasílání MultiCast
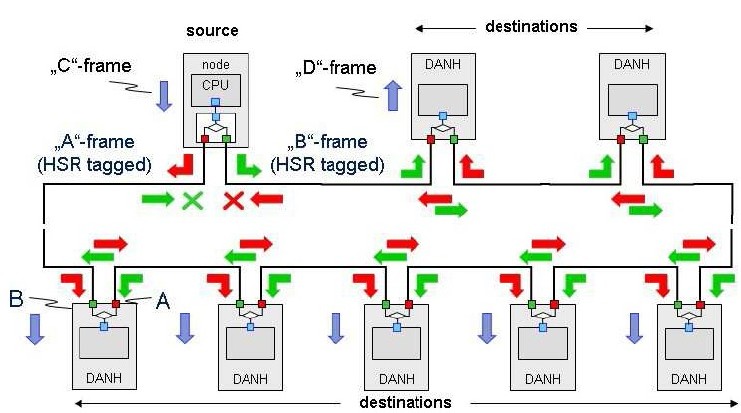
Pro každý zaslaný rámec („C“-frame), pošle zdrojový uzel dvě kopie – jednu přes port A a druhou přes B. Každý uzel přenáší zaslaný rámec z portu A na port B a naopak, mimo ty, které již byly předány. Každý cílový uzel použije z této dvojice dříve přijatý rámec („D“-frame), ale již nepoužije jeho duplikát. Protože se jedná o MultiCast, oběhnou rámce kruh v obou směrech. Když dorazí až nazpět ke zdroji, ten je musí následně vyřadit z provozu. Jinak by obíhali nekonečně dlouho a postupně by s dalšími rámci zahltili celou síť. Zdrojový uzel tedy odstraní z kruhu rámce zaslané jeho druhým portem. Pokud kruh je přerušen/poškozen, rámce dorazí ještě přes neporušenou část kruhu bez vlivu na chod aplikace. Ztráta integrity kruhu je snadno detekována, protože přestaly přicházet duplikáty rámců.
Princip zasílání UniCast
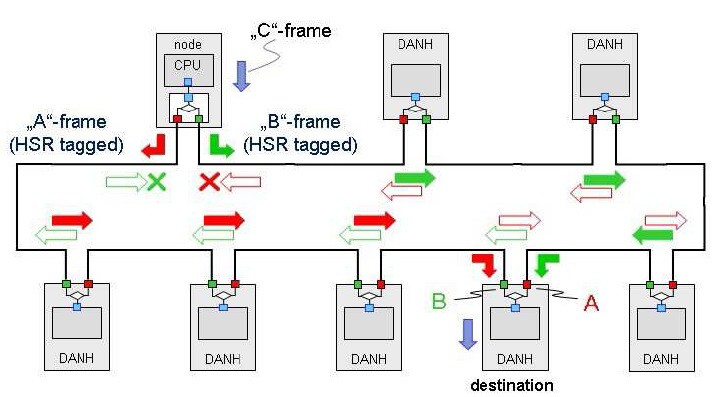
Každý uzel přenáší zaslaný rámec z portu A na port B a naopak, mimo ty, které již byly předány nebo dorazily. Protože se jedná o Unicast, oba rámce vyřazuje cílový uzel. Pokud kruh je přerušen/poškozen, rámce dorazí ještě přes neporušenou část kruhu bez vlivu na chod aplikace. Ztráta integrity kruhu je detekována, protože přestaly přicházet duplikáty rámců.
Pro vysvětlení, jak se detekuje HSR rámec musíme alespoň malinko zabřednout do problematiky přenosových rámců EtherNetu. Nemůžeme se touto problematikou zabývat hlouběji, neboť typů rámců je tolik, že by to vydalo na hodně tlustou knihu a než by se dopsala, byly by nové. Tudíž alespoň to základní.
EtherNet rámec rozšířený o VLAN

Význam většiny polí vyplývá z obrázku. Popíši pouze ty, která mohou mít více významů.
ETPID – Ethernet protocol ID (VLAN protokol ID) – jedná se o takzvaný identifikátor typu rámce a obsahuje hodnotu 8100H. Pro zařízení, která pracují s VLAN je to identifikátor toho, že další dva oktety ponesou informace o VLAN.
LT (Lenght/Type) / LLC (Logical Link Control)
– pro Ethernet II je to pole určující typ vyššího protokolu
– pro IEEE 802.3 udává délku pole dat (pro IEEE 802.3 udává délku pole dat)
– pro IEEE 802.3x má toto pole význam délky pouze pokud obsahuje hodnotu max. 1500 (05DC hex), pokud obsahuje hodnotu alespoň 1536 (0600 hex), jedná se o typ)
EtherNet rámec HSR

HSR rámec využívá právě pole Tagu. V části ETPID má uvedenu hodnotu 892F, která je přiřazena pro HSR a žádný jiný systém ji nesmí používat. Další části TF jsou využity pro Path indicator (vpravo/vlevo tj. zda jde o první snímek nebo duplikát), Size Field a Sequence Number. Tyto informace byly vloženy jako HSR tag stejným způsobem jako je vložen VLAN tag. Odesílatel vloží stejné pořadové číslo rámce (sequence number) do obou rámců zasílané dvojice a inkrementuje sequence counter pro každé zaslání z tohoto uzlu. Přijímač sleduje sequence counter pro každý zdroj MAC adresy přijímaných rámců. Rámce se stejným zdrojem a stejnou hodnotou sequence number přicházející z druhého směru jsou odstraněny. Supervise sítě v uzlu vede tabulku všech ostatních uzlů v síti, ze které se dostává rámce. To umožňuje detekovat absenci uzlů a chybu linky. Uzel odesílá rámec prostřednictvím své zdrojové adresy a sequence numer.
Běžné síťové zařízení nezná v ETPID hodnotu 892F. Pokud dostane takový rámec, prostě jej zahodí v domnění, že je poškozený. HSR rámce se tedy mohou pohybovat pouze v HSR síti. Vzniká tedy technologicky privátní síť. Navíc šest oktetů vloženého HSR Tagu může generovat příliš velké rámce (s více než 1522 Byte). Nicméně HSR Ring je kruh s privátním provozem a neovlivňuje ostatní EtherNet kontrolery.
Každý uzel má stejnou MAC adresu na obou HSR portech i stejnou IP adresu pro oba porty (uzel může reagovat na několik IP adres). Proto řízení jako je např. protokol ARP pracuje jako obvykle a přiřadí tuto MAC adresu k IP adrese tohoto uzlu. TCP/IP nezná redundanci na Layer 2, a to je důvodem nutnosti vyřazování duplikátů.
Jak tedy připojit k HSR kruhu zařízení, která nejsou HSR typu (starší uzly, PC, notebooky nebo tiskárny) a neznají HSR Tag. Ta musí být připojena přes RedBox (redundance Box), který působí jako jejich zástupce. RedBox generuje stejné rámce, které posílají uzly vložené do ringu a odstraňuje jejich duplikáty.
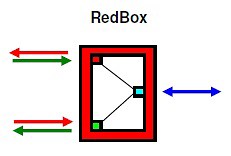
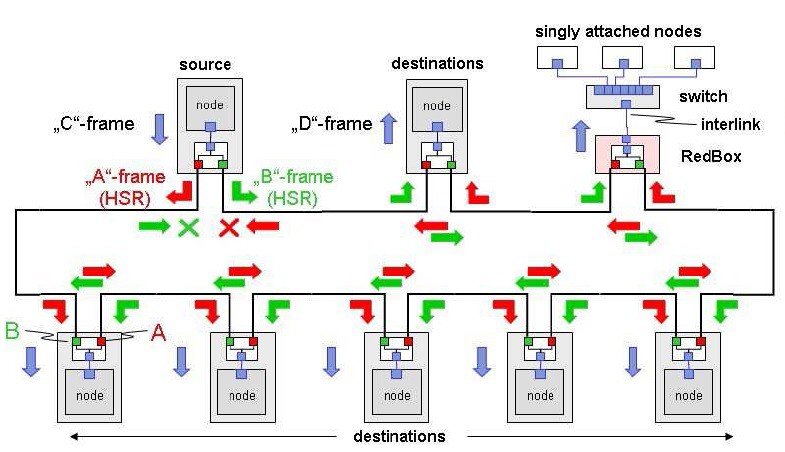
RedBox funguje jako proxy pro řadu samostatně připojených uzlů. Pro odstranění duplikátů rámců z Ringu vede RedBox tabulku uzlů, pro které funguje jako proxy server, např. při odposlechu přijímaných rámců (8). Tak může ping SANs vyčistit z tabulky odstraněné nebo nefunkční uzly, nebo odstranit položky po time-out (např. 1 min.). RedBox se chová jako bridge pro non-HSR provoz. Je to ve skutečnosti speciální Switch, který má dva porty HSR (obvykle port 1 a 2) a další porty jsou non-HSR.
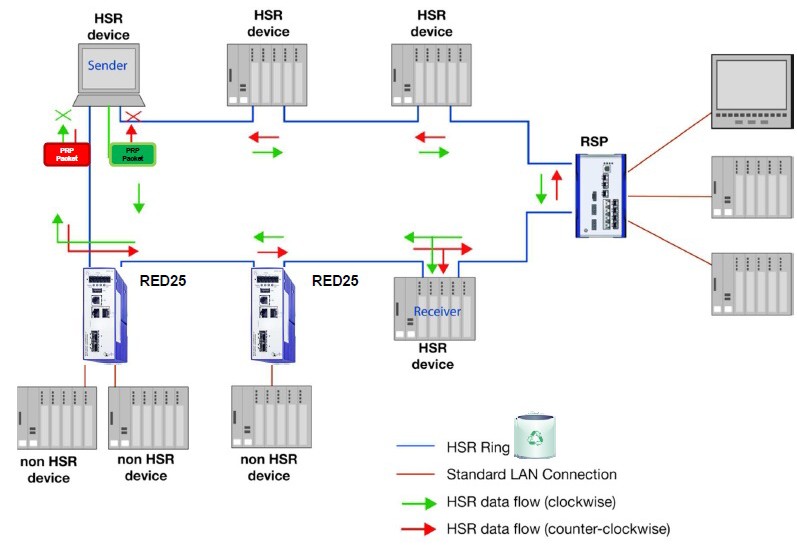
V reálném prostředí bude určitě nutné propojit HSR ring s prostředím, které zajišťuje redundanci jinými prostředky. Jednu z mnoha možností představuje řešení z následujícího obrázku.
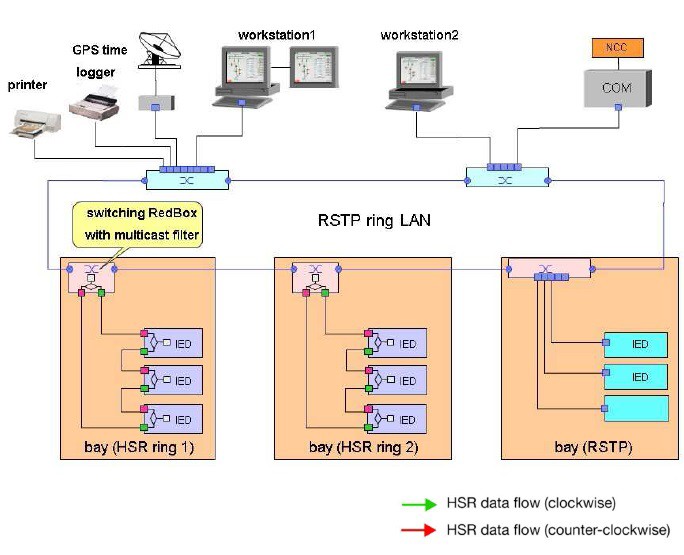
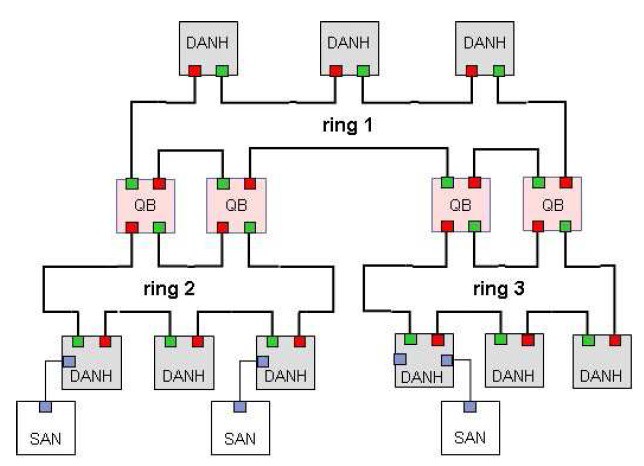
Pro redundantní propojení dvou HSR kruhů potřebujeme zařízení nazvané QuadBox.
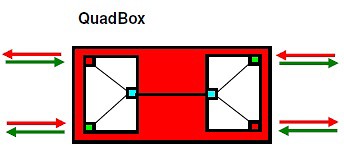
Ten vzniká propojením dvou RedBoxů přes non-HSR porty. Může být provedena i agregace portů v tomto propojení. Pro redundantní propojení dvou HSR ringů jsou potřebné dva takové QuadBoxy.
Topologie s plným pokrytím: ring z ringů
Pro redundantní propojení každých dvou HSR ringů potřebujeme vždy dva QuadBoxy.
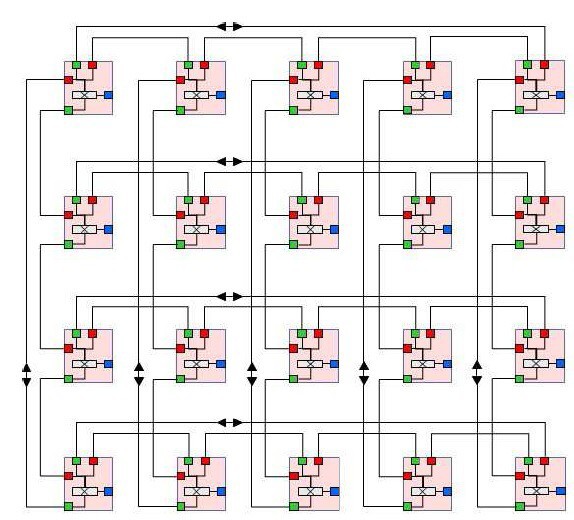
Pomocí HSR Ringů můžeme řídit i Transputer topologii.
HSR – pozitiva a negativa
Pozitiva:
- rychlý přenos mezi uzly. Uzel nezpracovává celý rámec, pokud není cílem. Dekóduje pouze cílovou adresu a poškození rámce. Dále už rámec ihned přeposílá.
- nulová doba rekonfigurace na záložní trasu
- možnost vícenásobných redundancí – až po Trasputer topologii
- možnost režimu Real-Time
Negativa:
- vychází z topologie Ring (nemusí být vhodné pro všechny případy)
- zasíláním duplikátů rámců je dosaženo dvojnásobné zátěže sítě – cena za řešení
- potřeba speciálního hardware (nebo v dnešní době spíše firmware)
PRP – Parallel Redundancy Protocol
zdroj volného zpracování: presentace Prof. Dr. Hubert Kirrmann, ABB Switzerland Ltd.
Druhým řešením řízení sítě s nulovým časem rekonfigurace sítě na záložní je PRP. Na rozdíl od HSR je toto řešení nezávislé na topologii. Může tedy pracovat nejen v kruhu, ale v sítích se strukturou hvězdy, stromu atd. Každý uzel má opět dva porty, které mají stejnou MAC adresu i IP adresu. Každý z těchto portů je napojen do jedné ze dvou fyzicky oddělených paralelně fungujících sítí.
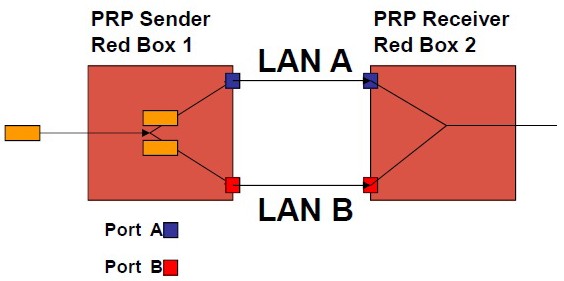
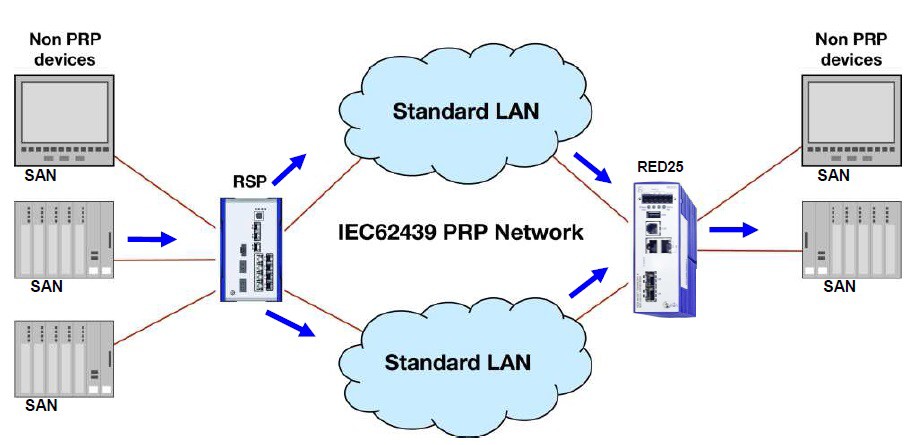
Dvě oddělené Ethernet sítě (LAN) podobné topologie a rozsahu pracují paralelně. Každý dvojnásobně připojený uzel s PRP (DANP) má rozhraní pro každou LAN. Zdroj DANP odešle rámec současně do obou LAN. DANP cíl dostane při běžném provozu oba rámce a zahodí duplikát. Jednotlivě připojené zařízení (SAN) obdrží pouze jeden rámec. Pokud selže jedna LAN, cílové DANP pracuje s rámy z druhé LAN. Problém vznikne v případě SAN, která budou připojena způsobem pouze do jedné sítě. Pokud selže síť, ke které jsou tato SAN připojena, nemají náhradní zdroj informací. Stejně jako u HSR je možné SAN připojit přes RedBox a tím vyřešit uvedený problém.
Akceptace a odstranění duplikátů PRP
Každý uzel obdrží stejný rámec dvakrát, pokud pracují obě redundantní LAN bezchybně.
Teoreticky není třeba odstraňovat duplikáty na linkové vrstvě. Jakákoli komunikace nebo aplikační software musí být schopen vypořádat se s duplikáty. Přepínání sítí (např. 802.1D RSTP) může vygenerovat duplikáty. Většina aplikací pracuje nad TCP, který byl navržen tak, aby se duplikátů zbavil. Aplikace na UDP nebo L2 protokolech (publisher/subscriber), musí být schopny ignorovat duplikáty, protože jsou závislé na nespojované komunikaci. PRP může fungovat bez filtrace duplikátů. Režim “ Duplicate Accept“, který se používá pro testování. Pro běžný provoz PRP používá režim „Duplicate Discard“, ve kterém duplikáty odstraňuje. Je to potřebné především pro řízení a kontrolu redundance.
A opět trochu z problematiky rámců. PRP nevyužívá pro označení TF. Proto nyní pro vysvětlení použijeme rámec bez TF. Samozřejmě, že PRP může používat i rámce s TF při zachování původního významu a funkce tohoto pole.
EtherNet rámec bez TF VLAN

EtherNet rámec PRP

PRP nevyužívá na rozdíl od HSR pro svou identifikaci Tag Field, ale má vlastní značení v koncové části datového pole. To se zkrátí o 4 oktety. V nich je umístěn PRP sufix, sequence counter, lan indicator, a size field. Tím, že je to vloženo do datové části rámce, je to pro normální provoz neviditelné. Žádné zařízení na L2 nečte obsah datové části rámce. Tudíž PRP rámce jsou bez problémů přijaty a zpracovány jakýmkoliv EtherNet zařízením. Umístění PRP sufixu za payload umožňuje SAN (uzly, které neumí PRP – jednotlivě připojené uzly, jako jsou přenosné počítače apod.), aby akceptovali PRP rámce. Všechny jednotlivě připojené uzly ignorují oktety mezi payload a FCS, protože je považují za výplň – padding. Z tohoto důvodu mají všechny protokoly postavené na vrstvě 2 samostatně pole (LT) s informací o velikosti payload a samostatně kontrolní součet FCS.
Princip funkce PRP je prakticky shodný s HSR. Odesílatel vloží stejnou hodnotu sequence counter do obou snímků dvojice a zvýší ji o jednu pro každý další poslaný rámec. Přijímač sleduje sequence counter pro každý pro každý zdroj (dle MAC adresy). Rámec se stejným zdrojem a sequence counter přicházející z druhé LAN je ignorován. Pro dohled nad sítí udržuje každý uzel tabulku všech jiných uzlů v síti. To umožňuje detekovat absenci uzlů i chyby linek ve stejnou dobu.
Ukažme si nyní několik variant řešení s PRP.
Do obou sítí jsou připojena na přímo zařízení typu PRP a přes RedBox (Switch řady RSP) jsou připojeno non-PRP SAN¨.
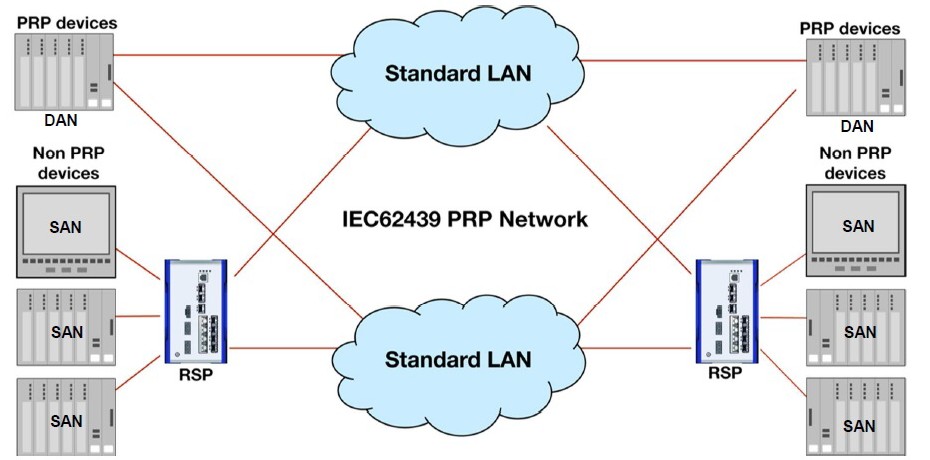
Vnitřní propojení obou ekvivalentních LAN může obsahovat vlastní řešení redundancí v rámci těchto sítí. Tím je myšleno cokoliv z dříve uvedených topologií i protokolů řízení redundance. Nic z toho nebude v kolizi s PRP
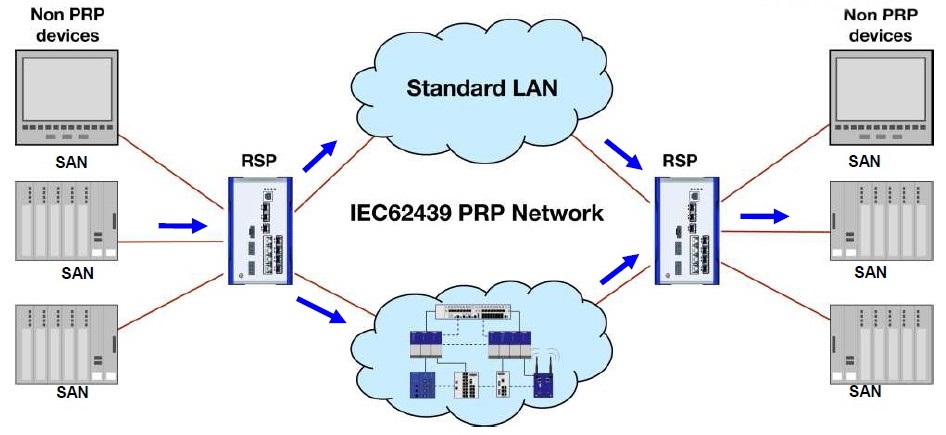
Dokonce je možné jednu (nebo obě) z uvedených sítí řešit jako Wireless (WiFi). Na přenosu přes dvě různé cesty je důležitý pouze rozdíl ve zpoždění.
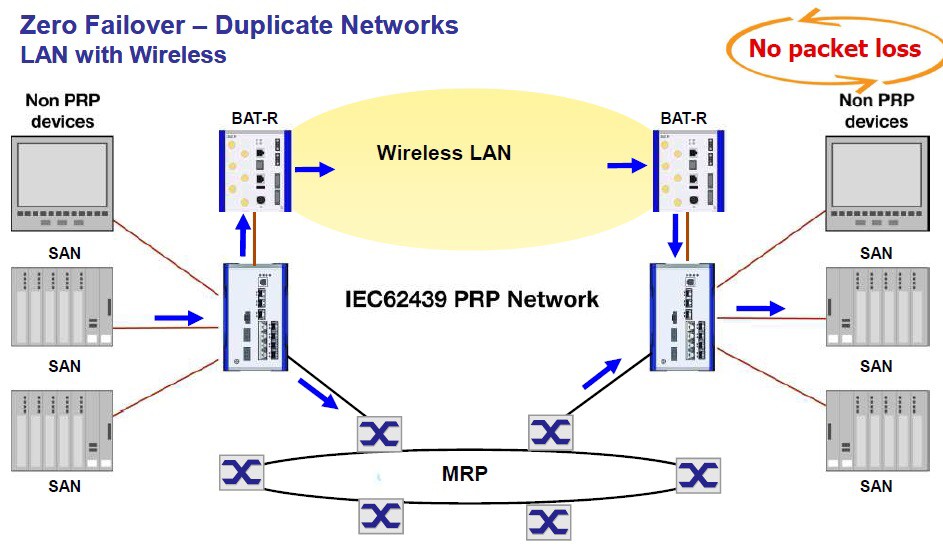
Existují i dvojité WiFi, které samy fungují jako RedBox a umožňují vytvoření PRP spoje s protější stranou.
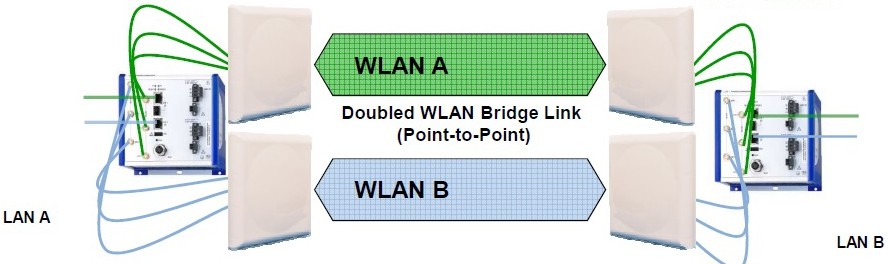
PRP – pozitiva a negativa
Pozitiva:
- nulová doba rekonfigurace na záložní trasu
- nezávislé na topologii
- aplikačně nezávislé, hodí se do všech sítí Ethernet
- používá standardní přepínače a nemodifikované protokoly (ARP, DHCP, TCP / IP, …)
- umožňuje připojení uzlů s jakýmkoliv portem jiného uzlu do jedné sítě (bez redundance)
- neporušuje nezávislost řízení jiných redundantních sítí
- monitoruje neustále redundanci obou aktivních LAN
- monitoruje aktuální topografie obou sítí (přes správu sítě / SNMP)
- kompatibilní s IEEE 1588v2 (PTPv2) – redundantní hodiny
- není potřeba speciálního hardware jako u HSR
Negativa:
- vyžaduje zdvojení sítě – cena za jakékoli řešení plné redundance
- omezeno L2 broadcast doménou
- vyžaduje, aby jednotlivě připojené uzly, které potřebují komunikovat spolu navzájem, byly všechny ve stejné síti LAN (nebo připojeny přes „RedBox“)
- stojí režii čtyři oktety v Ethernet rámci
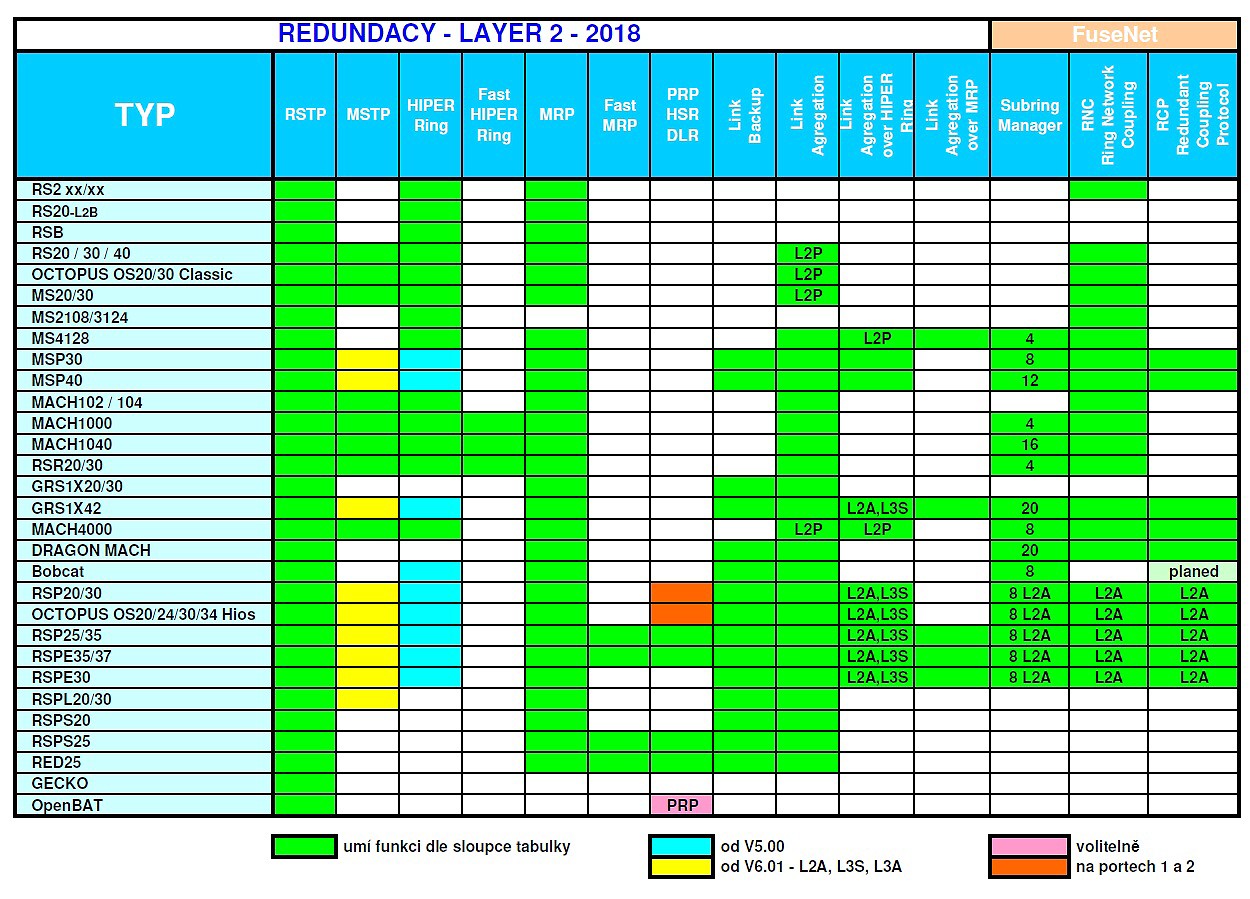
Přehled ověřených funkcí redundance jednotlivých typových řad Switchů
Protokoly redundance na L3
Závěrem ještě pár informací k redundancím na L3.
Ve vysokorychlostních páteřních sítích se prosazuje MPLS (Multiprotocol Label Switching). Tato metoda používá krátká navěstí pevné délky, která identifikují virtuální spoje a je nezávislá na síťových protokolech. Na internetu je dostatek informačních zdrojů, které tuto metodu detailně popisují. Nebudeme se jí tedy podrobně zabývat.
VRRP – Virtual Router Redundancy Protocol
Toto řešení používají převážně zařízení typu Security Router/FireWall .Ten vykonává v plném rozsahu funkci Firewallu mezi dvěma sítěmi s odlišným IP adresním prostorem. VRRP používá principu virtuálního routeru vytvořeného z několika fyzických (viz následující obrázek).
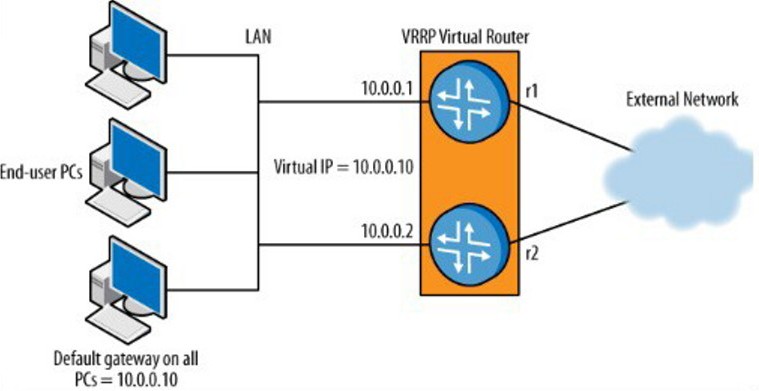
U všech fyzických rourerů se nastaví jejich virtuální adresa (vnější i vnitřní), která je stejná pro všechny začleněné routery. Následně se každému přidělí seznam partnerských fyzických routerů a stanoví priorita, dle které se budou zastupovat v případě výpadku.
Všechny fyzické firewally začleněné do virtuálního si neustále vyměňují informace o stavu přes vnitřní i vnější rozhraní. Mají tedy nestálý přehled o vzájemné dostupnosti přes obě sítě. Pokud je na některém rozhraní Firewallu s vyšší prioritou ztracena dostupnost, druhý okamžitě přebírá jeho funkci.
Teoreticky je možné zařadit do virtuálního routeru velké množství fyzických. Prakticky je to omezeno řešením jednotlivých výrobců (možnost nastavení v MNG příslušného prvku). Většina výrobců doporučuje použití dvou fyzických routerů.